深度学习中的「卷积层」如何深入理解?
「雷克世界」编译:嗯~阿童木呀 多啦A亮
当前深度学习领域非常火热,其中卷积网络是促成众多令人瞩目成就的关键因素。自从2012年AlexNet问世以来,如今几乎找不到一个突破性的计算机视觉方案完全不采用卷积结构。
当前深度学习体系中,我们编写的卷积层通常由简短指令构成,该指令能够概括诸多构造要素。然而开yun体育app入口登录,偶尔从宏观视角审视某些抽象原理,同样具有价值。本文着重分析卷积层的一个独特构造方面,这一方面在多数文献及讨论中鲜有提及。
一些卷积结构以一个外部卷积模块为起点,该模块负责把RGB通道的输入图像转换为一组内部滤波器。在目前应用最广泛的深度学习平台里,实现这个功能的代码大概是这样的:
out_1是卷积操作的结果,输入图像经过处理,过滤器数量为三十二,卷积核大小为三行三列,步长设置为每行每列移动一个像素点
relu_out=relu(out_1)
池化层接收relu层输出,窗口大小设定为2x2,步长为2进行下采样,结果存储在pool_out变量中
对于很多人而言,明白先前展示的成果实际上是由若干深度达三十二级的过滤器构成,这一点显而易见。然而,具体怎样才能将拥有三个通道的图像精准地对应到这三十两个层级上,目前尚无定论。同样地,关于如何运用最大池化这一运算符也存在疑问。譬如,是否应该将最大池化同时作用于所有过滤层级,从而高效地构建出一个统一的过滤映射?或者,能否让最大池单独作用于每个过滤器,从而得到32层规格的池化过滤器?
如何做
一张图胜过万语千言,下面呈现一个图表,能够展现先前代码片段里所有步骤。
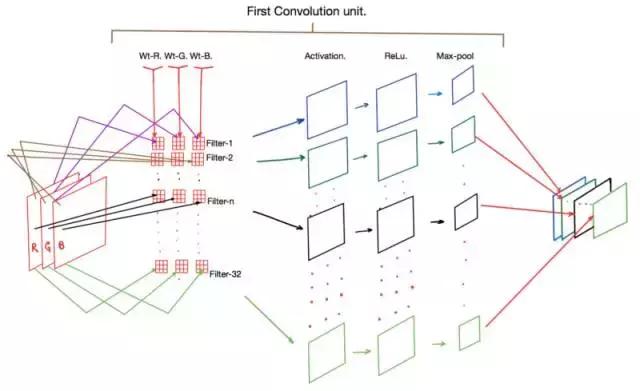
卷积层的应用
看图可知,一个明显之处在于,步骤1里每个过滤器,也就是过滤器-1、过滤器-2等,实际上由三个卷积核组成,分别是Wt-R、Wt-G和WT-B。这些核各自储存了输入图像的红(R)、绿(G)和蓝(B)信道信息。
正向传播时,图像里红绿蓝各色像素值要分别和Wt-R、Wt-G、Wt-B这些核心相乘,得出一个时断时续的激活图,这个图在图里没有画出。接着把这三个核心的输出结果加在一起,这样每个过滤器就能得到一个激活图。
接下来,每个激活都要经过ReLu函数处理,然后传递给最大池化层,这个层的主要作用是降低输出激活图的维度。最终,我们得到一组激活图,它们的维度通常是输入图像的一半,但现在信号被组织成了32个选定过滤器构成的二维张量。
卷积层的结果常常被当作下一级卷积层的数据来源,所以开元棋官方正版下载,假如我们的第二个卷积部分是:
conv_out_2 = 卷积层设置输入为 relu_out, 独立输出通道数量为 64
那么这个结构要创建64个处理单元,每个单元配备一套独立的32个核心组件。
为什么
另有一点值得注意,那就是为何首个卷积层选用了32个滤波器。在诸多常见架构里,随着网络层次加深,所配置的滤波器数目会逐步增加,比如后续第二层使用64个,第三层则配置128个,以此类推。
本文中开yun体育官网入口登录app,Matt Zeiler借助一种逆向卷积方法,实现了对深度卷积构造各层级的核心在训练期间进行校准的可视化。通常认为,当卷积网络达到最佳训练状态时,位于边缘(即贴近图像部分)的滤波器会对基础边缘和基本纹理产生反应。而处于内部的过滤器,则对逐步增加的复杂形状和模式表现出敏感性。这些现象在Matt论文的图表中得到了很好的总结:

在第一层和第二层(最外层)上过滤器激活的可视化

第三层过滤器激活的可视化

第4层和第5层的过滤器的可视化激活
另有一个我思索许久的话题是,为何各类筛选器,即便处在同一层级,其形态或样式也趋于一致。毕竟,任何核函数的参数都并无显著差异,这可解释所见现象。关键在于:随机梯度下降法会自动修正参数,令核函数具备前述特性。核心要素是:
初始时核值是随机设定的,目的是让每个核都能达到一个与众不同的最佳解。
我们设定了相当数量的筛选装置,用以尽可能捕捉数据整体中的各类特性,并且兼顾了运算所需付出的代价。
最后,一些研究报告称,过滤器激活的可视化有助于揭示卷积结构的效能。表现均衡且效果出色的网络,其激活模式通常呈现明确的边缘特征,同时形状检测器的表现也符合前述描述。而那些存在过度拟合、欠拟合或泛化问题的网络,则往往难以呈现出这些现象。因此,可以借助(2)中的方法来检验网络,目的是考察实验性的卷积网络是否得出了理想的效果。




