解惑!卷积神经网络原来是这样实现图像识别的
来源:mindmajix.com
「机器人圈」编译:多啦A亮
图像识别是一个既吸引人又充满难度的探索方向。这篇文章介绍了卷积神经网络在图像识别方面的理念、实践以及相关方法。
什么是图像识别,为什么要使用它?
图像识别是机器视觉里的一个方面,软件能够通过这种方式分辨出人物、场景、物体、动作以及图像记录的内容。要达成图像识别这个目标,计算机需要借助人工智能软件和摄像设备,并且运用机器视觉技术。
人类与动物的大脑在辨认物体时十分便捷,而计算机面对同类任务却倍感吃力。我们观察树木、车辆或同伴时,通常无需刻意记忆就能知晓其身份。不过对机器而言,识别各类物件——诸如时钟、桌椅、人或动物——均属棘手挑战,且寻求破解之道代价极大。
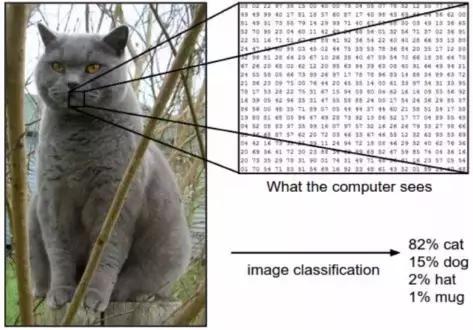
图片:CS231.github
图像识别属于机器学习范畴,其构建思路效仿了人脑的运作机制。借助这种技术,电脑能够辨识出图像里的各种视觉成分。凭借庞大的资料库和留意浮现的规律,机器可以解析图像,并为其分配相应的标记和归类。
图像识别的流行应用
图像识别用途广泛。个人照片整理最为常见且广受欢迎。借助图像识别技术,照片管理软件的用户体验持续优化。此类应用不仅具备照片存储功能,还增强了资料检索和内容发掘方面的性能。用户可利用机器学习赋予的自动图像归类能力达成此目标。嵌入软件的视觉解析工具依据辨识的图形对照片实施归类,同时将它们划分成若干类别。
图像识别的其它用途涵盖全景图库和视频平台,也包括互动营销和创意策划,还有社交网络中的人脸与图像辨认,以及拥有庞大视觉档案的网站的图像归类。
图像识别是一项艰巨的任务
图像识别并非易事。采用元数据管理非结构化资料是一种可行途径。人工请专家给音乐和电影库打标签或许很费劲,但若要处理自动驾驶汽车导航系统中的难题,比如区分路上的行人及各类车辆,或是筛选、归类、标记社交媒体每日涌现的上千万视频图片,那简直难于登天。
处理这个难题的一种途径是借助神经网络技术,通过常规神经网络在理论层面剖析图像,然而实际操作中,从计算资源消耗角度考量,代价会极其高昂,比如一个试图将小图像(调整为30乘30像素)处理的普通神经网络,即便如此也需要五十万个参数以及九百个输入量一种性能优越的设备能够应对这种状况,不过,当图像尺寸增大(比如变成500乘以500个像素点),所需要的参数和输入量便会急剧攀升。
图像识别神经网络运用中还存在另一个挑战,即过度拟合现象。这种现象通常出现在模型结构与其已学习的数据高度相似的情况下。这种情况往往造成两个后果,一是需要增加额外参数,从而提升计算负担,二是模型在面对新数据时会表现出泛化能力的减弱。
卷积神经网络
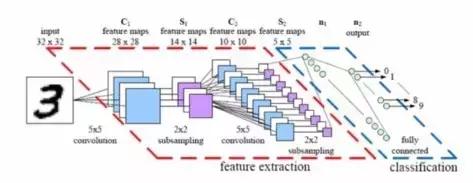
卷积神经网络架构模型
从神经网络构造方面来说,一个较为基础性的调整能让处理大幅图像变得更加方便,这就是我们所说的CNN或者ConvNets。
神经网络具备广泛的应用能力,这算是一种长处,不过,当用来分析图像时,这种好处反而成了阻碍。卷积神经网络做出了一个有趣的取舍:假如一个网络是专门为图像分析而构建的,那么为了得到更实用的效果,就必须放弃部分通用性。
当涉及图像时,位置邻近性与像素间相似度关联密切,卷积神经网络正是基于此原理设计而成。具体而言开yun体育app入口登录,同一图像内相邻的像素点,其关联性通常高于相距较远的像素点。但传统神经网络中,每个像素点都与所有神经元建立连接。由此带来的计算压力,导致网络在处理这类情况时效果欠佳。
卷积通过去除大量次要的关联,化解了这一难题。用专业表述来说,卷积神经网络让图像分析能够借助邻近性对关联实施筛选,从而得出易于处理的计算结果。在某个层级上开yun体育官网入口登录app,卷积神经网络并非将每个输入都与所有神经元相连,而是刻意约束了关联,确保任一神经元仅从前一层的一个小范围获取信息(比如5 * 5或3 * 3像素的区域)。所以,单个神经细胞仅负责分析图像中的局部区域,换句话说,这种工作方式与大脑中个体皮质神经元的功能相似,它们各自只对整体视觉范围的一个小片段产生反应。
卷积神经网络的工作过程
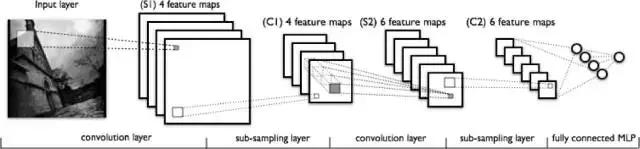
图片:deeplearning4j
在上图中从左到右,你可以观察到:
·对特征进行扫描的真实输入图像。通过它的过滤器是光矩形。
映射激活设置在堆栈顶端,每个筛选器另设一个映射。较大的矩形区域是执行下采样的单元。
·激活图通过下采样进行压缩。
·通过将过滤器通过堆栈进行下采样生成的一组新的激活映射。
·第二次下采样——将第二组激活图压缩。
·完全连接层,每个节点指定1个标签的输出。
CNN运用邻近连接进行筛选的奥秘在于引入了两种创新的结构:池化环节和卷积环节。我们将分步阐释这一机制:比如,某个环节专门用于判断图像中是否出现了祖父的形象。
该过程的第一步是卷积层,其本身又包含几个步骤。
我们首先要把祖父的照片分割成若干块,每块是3 * 3个像素的小方格,这些小方格要彼此覆盖着排列。
接下来开元ky888棋牌官方版,我们借助一个构造简单的单层神经网络来执行这些图块的组合,权重参数不做调整。对图块进行各种排列,并且确保每个图像的尺寸保持较小,即3 * 3的规格,这样神经网络在处理时能够维持其高效性与精简性。
接下来,需要把图像里各部分信息的数值数组按照坐标轴排列出来,这个坐标轴包含颜色、宽度和高度数据,因此每个拼图在这种情况下都会形成一个3 * 3 * 3的立体数据结构,如果讨论祖父的视频资料,那么会多出一个时间维度。
接下来是汇聚层,该层处理这些三或四维矩阵,结合空间信息执行降采样操作。输出是一个汇聚矩阵,里面只保留关键的图像区域,舍弃了其他内容。这样做有效降低了计算负担,还能防止模型出现过度学习现象。
以降采样矩阵充当标准全连接神经网络的起始数据。因为借助池化与卷积操作,输入的维度已显著压缩,因此需要为普通网络提供适宜处理的单元,并确保关键信息得以保存。最终结果将反映系统对祖辈影像的信任程度。
实际情形中,卷积神经网络的运作机制十分繁复,包含诸多隐含层、下采样层和卷积层。再者,标准的卷积网络往往处理成百上千个分类目标,而非仅有一个分类任务。
如何构建卷积神经网络?
从头打造卷积神经网络或许代价高昂且费时费力。不过当前人们已推出若干应用程序接口,其目的在于帮助各机构获取专属认知,而无需自行钻研机器学习或计算机视觉相关学问。
谷歌 Cloud Vision
谷歌云视觉是谷歌的图像识别服务,通过HTTP接口实现。该服务采用开源的TensorFlow技术构建。它能识别独立的人脸和物体,并且具备相当丰富的分类标签库。
IBM沃森视觉识别
IBM沃森视觉识别属于沃森开发者云范畴,包含众多预设分类,其核心功能在于依据用户图像进行专属类别训练。该平台还具备多种高级特性,诸如NSFW内容识别与OCR文字检测,这些功能与Google Cloud Vision提供的相应能力相似。
Clarif.ai
Clarif.ai是一种新型的图像识别工具,同样支持REST API接口。该平台一个颇具特色的亮点在于内置了多个功能模块,能够协助用户针对特定领域进行算法的个性化调整,例如餐饮、旅游以及婚庆等场景。
虽然前面提到的那些应用程序接口主要服务于部分常规用途,不过针对具体工作目标,你或许还得单独设计专属的应用程序。好在目前市面上存在不少资源,它们能在算法优化和运算执行等环节提供便利,让从事编程和数据研究的从业者得以减轻负担,从而将精力集中在对模型的培养上。众多库,诸如Theano、Torch、DeepLearning4J和TensorFlow,已成功用于各类场景。
卷积神经网络的有趣应用
自动将声音添加到无声电影
系统需要生成声音来配合无声视频,为此它接受了大量训练。训练内容包括用鼓槌敲击各种物体,制造出不同的声响效果。深度学习模型会对比视频画面和预先录制的声音库,找出最符合当前场景的声音片段。评估过程类似图灵测试,参与者需要分辨视频中的声音是人工合成还是真实录制。这是卷积神经网和LSTM循环网的一种极有意思的应用方式,在视频里可以了解详情




