一文读懂 12种卷积方法
本文约7800字,建议阅读15分钟
本文对深度学习领域中广泛应用的各类卷积算法进行了梳理,同时,也将尝试采用一种易于大众理解的方法对这些算法进行阐述。
深度学习中的卷积概念至关重要,然而,你对这个领域的卷积究竟了解多少,以及它有多少种类型?近期,研究学者昆仑·白发表了一篇关于深度学习卷积的介绍性文章,以通俗易懂的方式阐述了该领域不同类型的卷积及其独特优势。由于篇幅较长,机器之心仅选取了部分内容进行展示,具体请参阅原文的第2、4、5、9、11、12节。
若你对深度学习领域内各式各样的卷积算法有所耳闻,诸如二维、三维、1x1、转置、扩张(Atrous)、空间可分、深度可分、平展、分组、混洗分组卷积等,却对其具体含义感到困惑,那么这篇内容正是针对你而设,旨在帮助你深入理解这些算法的实际运作机制。
本文将梳理深度学习领域频繁使用的各类卷积算法,并力求以通俗易懂的方法对这些算法进行阐述。
本文旨在助你建立起对卷积的直观理解,并有望成为你研究或学习过程中的有益参考资料。
本文目录
1. 卷积与互相关
2. 深度学习中的卷积(单通道版本,多通道版本)
3. 3D 卷积
4. 1×1 卷积
5. 卷积算术
6. 转置卷积(去卷积、棋盘效应)
7. 扩张卷积
8. 可分卷积(空间可分卷积,深度可分卷积)
9. 平展卷积
10. 分组卷积
11. 混洗分组卷积
12. 逐点分组卷积
一、卷积与互相关
在信号处理、图像处理等多个工程与科学分支中开yun体育官网入口登录app,卷积技术得到了广泛的应用。而在深度学习这一领域,卷积神经网络(CNN)这一模型架构正是基于此技术而命名。然而,在深度学习中,卷积的实质实际上是信号或图像处理中的互相关操作。这两种操作之间虽存在细微的差别。
无需深入探讨具体细节,我们便能够明显察觉到这一区别。在信号与图像处理这一领域中,卷积的概念可以这样表述:
该概念指的是通过将其中一个函数进行颠倒与平移处理,随后将两个处理后的函数相乘,最终得到的乘积再进行积分。接下来的图形化演示具体阐释了这一理念。
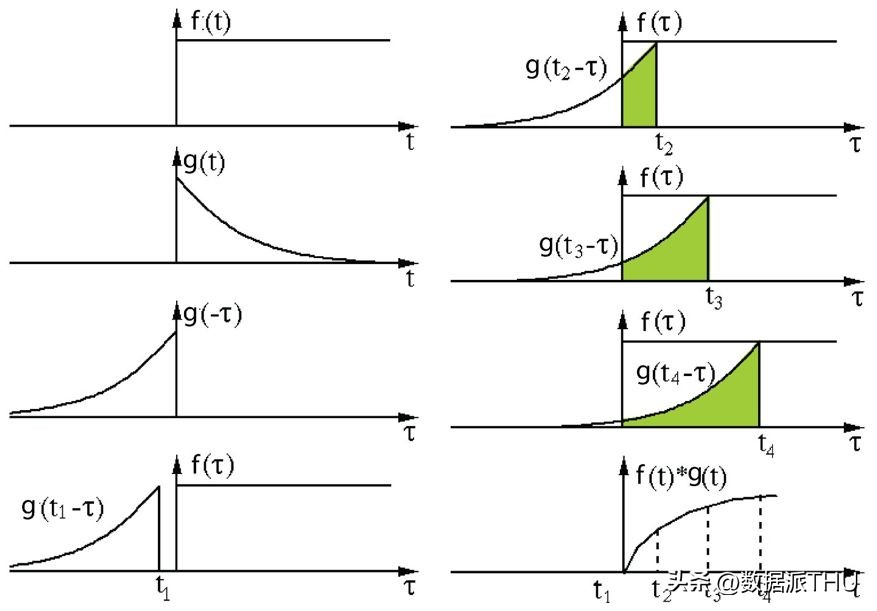
在信号处理领域,对卷积操作的理解至关重要。首先,将过滤器g进行反转处理,接着沿着水平方向进行滑动。在每个滑动位置,我们都会计算函数f与反转后的g所形成的交点构成的区域的面积。这个面积值,即为我们所求的特定位置的卷积结果。
在此情境下,函数g充当了过滤器的角色,经过反转处理并沿着水平方向进行移动。在每个特定的位置,我们都会对f与经过反转的g所形成的交叠部分进行面积测量。该交叠部分的面积,即为我们所求的特定位置的卷积数值。
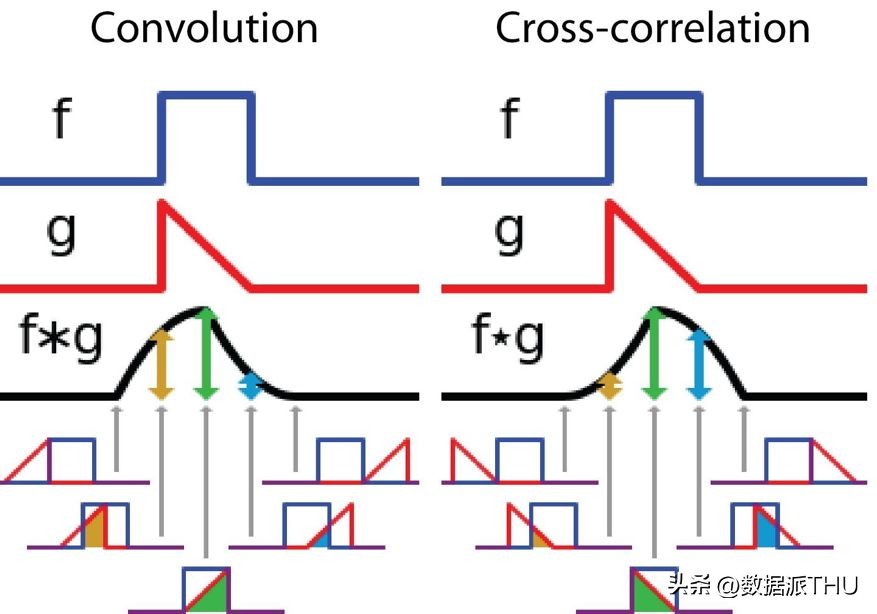
信号处理中卷积与互相关之间的差异
在深度学习领域,卷积操作中的过滤器并未进行反转处理。实际上,这属于互相关运算。我们实际上是在进行逐元素的乘法和加法运算。然而,在深度学习中,我们通常直接将其称作卷积,这样做更为简便。这并无不妥,因为过滤器的权重是在训练过程中学习得到的。假如上述例子中的反转函数g是正确的,那么经过训练后,我们学习到的过滤器将呈现出与反转后的函数g相似的特征。在开始训练之前,无需像在现实卷积操作中那样,先行对过滤器进行反转处理。
二、3D 卷积
在先前的阐述中,我们注意到自己其实是在对一个三维体积进行卷积操作。然而,在深度学习领域,我们通常依然将其称作二维卷积。这种二维卷积是在三维体积数据上进行的。其中,过滤器的深度与输入层的深度保持一致。此3D过滤器只在两个维度上移动(即图像的高度和宽度)。通过这样的处理,我们得到的结果是一张二维图像,且该图像仅包含一个通道。
显然,3D卷积确实是一种存在的技术。它可以说是2D卷积的一种推广。具体来说,3D卷积的过滤器深度要小于输入层的深度(即核大小大于m),因此比例关系变为2除以m。换句话说,在N远大于m的这种渐进情况下,当过滤器尺寸为3×3时,空间可分卷积的计算开销仅为标准卷积的2/3。当过滤器尺寸为5×5时,该数值降至2/5;若过滤器尺寸增至7×7,该数值进一步降至2/7。
空间可分卷积确实有助于降低成本,然而在深度学习中,它并不常见。一个关键因素在于,并非所有核都可以被拆分为两个更小的核。若将空间可分卷积全面替换传统卷积开yun体育app入口登录,这便限制了我们在训练阶段探索所有潜在核的能力。因此,所得到的训练效果可能并不理想。
2、深度可分卷积
深度可分卷积在深度学习领域中应用广泛,例如在MobileNet和Xception等模型中可见其身影。该技术涉及两个主要步骤:首先进行深度卷积核的1×1卷积操作。
在阐述这些操作步骤之前,我们得先回顾一下之前所讲解的2D卷积核中的1×1卷积。首先,简要回顾一下标准的2D卷积操作。以一个实例来说明,假如输入层的尺寸为7×7×3(代表高度、宽度和通道数),而使用的过滤器尺寸为3×3×3。经过一次2D卷积操作后,输出层的尺寸将变为5×5×1(仅包含一个通道)。
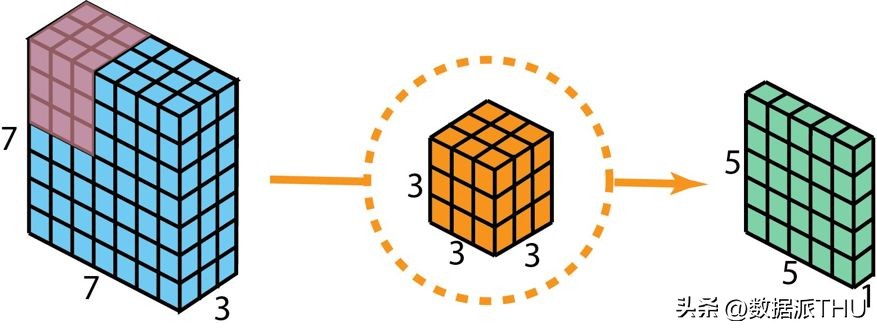
为了生成单层输出,该标准二维卷积采用了单一过滤器。
通常情况下,在两个神经网络层之间会部署多个过滤器。以本例为例,我们使用了128个这样的过滤器。经过这128个2D卷积的处理,我们得到了128个5×5×1尺寸的输出映射图。接着,我们将这些映射图层层叠加,最终形成了一个5×5×128尺寸的单层结构。通过执行此类操作,我们可以将输入层的尺寸(7×7×3)转变为输出层的尺寸(5×5×128)。在这个过程中,空间维度,也就是高度和宽度,将会减小,而深度则会相应增加。
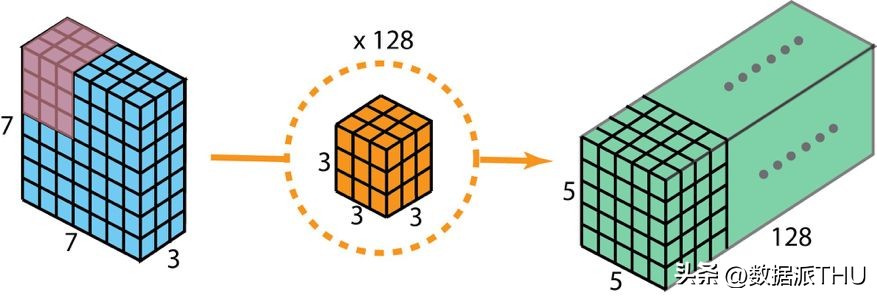
为了生成包含128层结构的二维卷积输出,需配备128个过滤器。
现在使用深度可分卷积,看看我们如何实现同样的变换。
我们将在输入层应用深度卷积技术。在此过程中,我们并未采用2D卷积中常见的3×3×3尺寸的单个过滤器,而是将其拆分为三个独立的核。这些核的尺寸均为3×3×1。每个核仅与输入层的一个特定通道进行卷积操作,而非对所有通道同时处理。通过这种方式,每一次卷积操作都能生成一个5×5×1尺寸的映射图。我们将这些映射图层层叠加,从而构建出一个5×5×3维度的图像矩阵。完成这一步骤后,我们便获得了5×5×3尺寸的输出结果。紧接着,我们能够减少图像的空间维度,而图像的深度则保持不变。
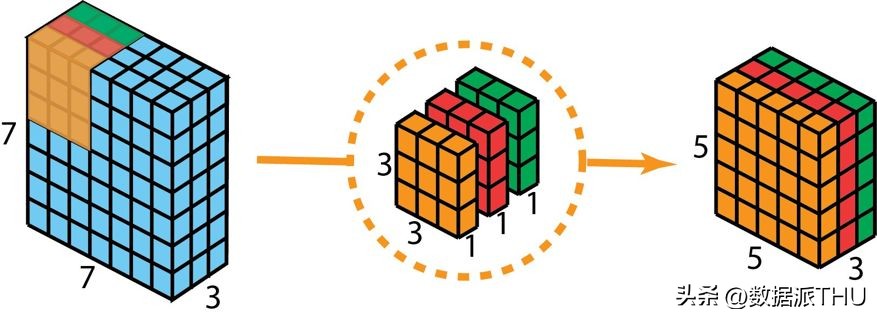
深度可分卷积——首先,我们摒弃了2D卷积中3×3×3的单个过滤器,转而采用三个独立的核。这些核的尺寸均为3×3×1。每个核仅与输入层的一个特定通道进行卷积操作,而非对所有通道同时处理。通过这种方式,每个卷积操作都能生成一个5×5×1的映射图。随后,我们将这些映射图逐层叠加,组合而成一个5×5×3维度的图像。完成这一步骤,我们便获得了尺寸为5×5×3的最终输出。
在深度可分卷积的第二阶段,我们采用了核尺寸为1×1×3的1×1卷积操作,以增加网络的深度。通过将5×5×3的输入图像与每个1×1×3的核进行卷积,我们能够生成一个5×5×1尺寸的映射图。
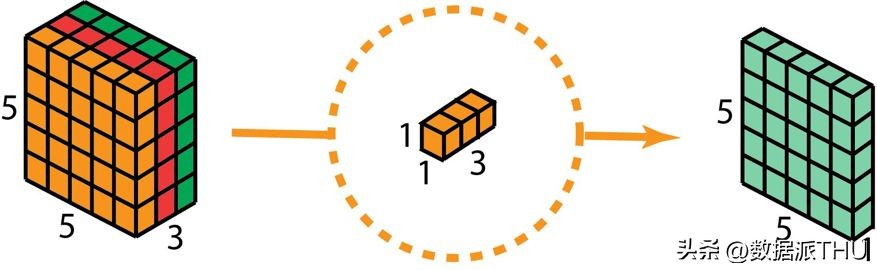
经过128次1×1卷积的应用,我们最终获得了尺寸为5×5×128的层。
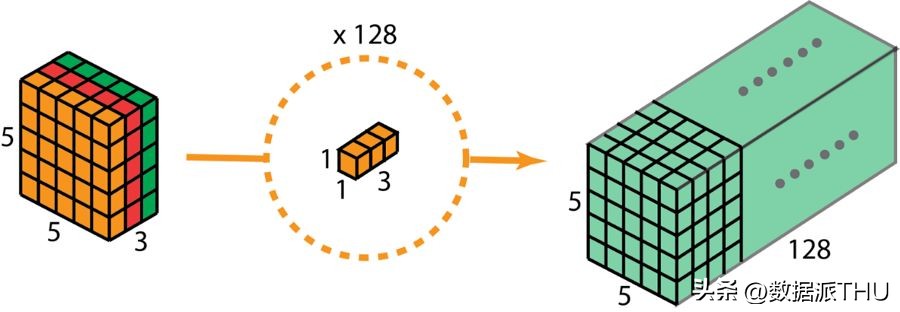
深度可分卷积——第二步:应用多个 1×1 卷积来修改深度。
经过这两个阶段,深度可分卷积神经网络能够将输入层的特征图(尺寸为7×7×3)转换并映射至输出层的特征图(尺寸为5×5×128)。
下图展示了深度可分卷积的整个过程。
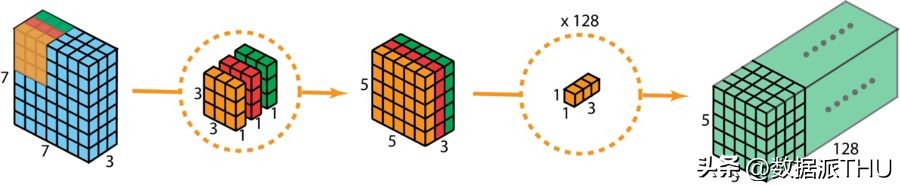
深度可分卷积的整个过程
那么,深度可分卷积究竟有哪些优点呢?答案是效率。与2D卷积相比,深度可分卷积在操作上所需步骤显著减少。
回顾我们之前讨论的二维卷积案例,该案例中包含128个3×3×3的核,这些核在5×5的区域内移动,共计进行了128次核的移动,每次移动涉及3×3×3的乘法运算,因此总共需要进行3×3×3×5×5×128次乘法运算,即86400次。
即便能够进行分卷积操作,但在初始的深度卷积阶段,存在三个3×3×1的核,它们以5×5的步长移动,总计进行了3x3x3x1x5x5等于675次乘法运算。随后,在第二个1×1卷积步骤中,有128个1×1×3的核同样以5×5的步长进行移动,这导致了128 x 1 x 1 x 3 x 5 x 5等于9600次的乘法计算。因此,深度可分卷积的计算量总计达到675次加上9600次,合计10275次乘法操作。与此相比,这一成本大约仅为2D卷积的12%。
因此,针对不同尺寸的图像,若采用深度可分卷积技术,我们能够缩减多少处理时间呢?接下来,以一个泛化的情形为例。对于一幅尺寸为 H×W×D 的输入图像,若以 Nc 个尺寸为 h×h×D 的卷积核进行二维卷积操作(设置步长为1,填充为0,且h为偶数尺寸)。为了实现输入层(H×W×D)向输出层((H-h+1)x (W-h+1) x Nc)的转换,必须进行的总乘法运算量包括:
Nc 乘以 h 乘以 h 乘以 D 乘以 (H减去h加1) 乘以 (W减去h加1)
另一方面,对于同样的变换,深度可分卷积所需的乘法次数为:
D乘以h乘以h乘以h减一乘以W减一加一,再加上Nc乘以1乘以1乘以D乘以h减一乘以W减一加一,等于h的平方加Nc乘以D乘以h减一乘以W减一加一。
则深度可分卷积与 2D 卷积所需的乘法次数比为:
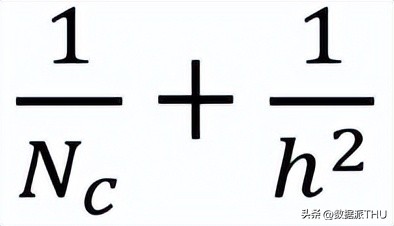
现代多数架构的输出层普遍包含众多通道,数量往往达到数百甚至上千。针对这类层(Nc远大于h),上述公式可以简化为1除以h的平方。据此,若采用3×3的滤波器,2D卷积所需的乘法运算量将是深度可分离卷积的9倍之多。而若选用5×5的滤波器,2D卷积所需的乘法运算量将是深度可分离卷积的25倍。
采用深度可分卷积是否存在弊端?答案是肯定的。深度可分卷积会减少卷积操作中的参数数量,这样一来,对于规模较小的模型来说,若以深度可分卷积替换2D卷积,其性能可能会明显减弱。结果可能是一个次优的模型。然而,若运用得当,深度可分卷积可以在不损害模型性能的前提下,助力实现效率的提升。
六、分组卷积
AlexNet的相关论文(可访问链接:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)于2012年首次提出了分组卷积的概念。主要采用分组卷积技术的目的在于,使得网络训练得以在内存资源受限的设备上完成,这类设备包括每个GPU仅拥有1.5GB内存的配置。以AlexNet为例,其结构中大多数层级均采用了两条独立的卷积通道。这一设计允许模型在两个GPU上实现并行处理(当然,若条件允许,也可扩展至更多GPU的并行处理)。
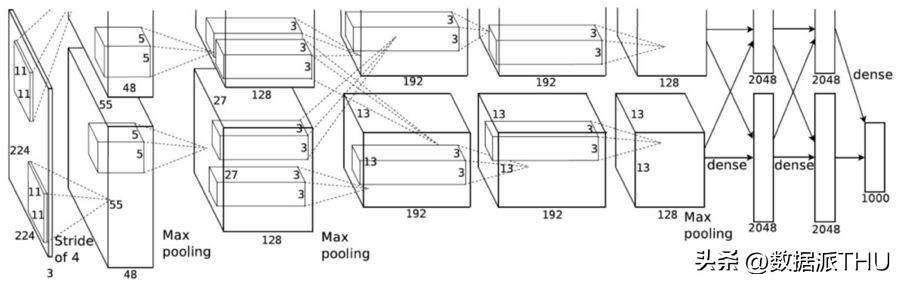
图片来自 AlexNet 论文
在此,我们将阐述分组卷积的操作原理。首先,一个典型的二维卷积过程,其步骤可参考下方的图示。具体来说,该示例中采用了128个尺寸为3×3×3的滤波器,将输入层的特征图(7×7×3)转换为了输出层的特征图(5×5×128)。推广开来,即通过使用Dout个尺寸为h x w x Din的核,将输入层的维度(Hin x Win x Din)转换至输出层的维度(Hout x Wout x Dout)。
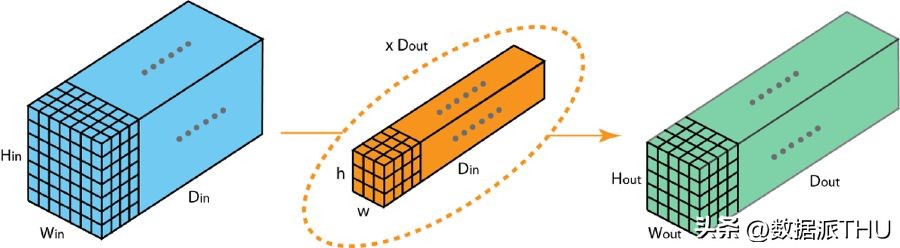
标准的 2D 卷积
在分组卷积操作中,过滤器被划分成若干个组别。每个组别均负责处理特定深度的典型二维卷积任务。以下实例可以帮助您更好地把握这一概念。
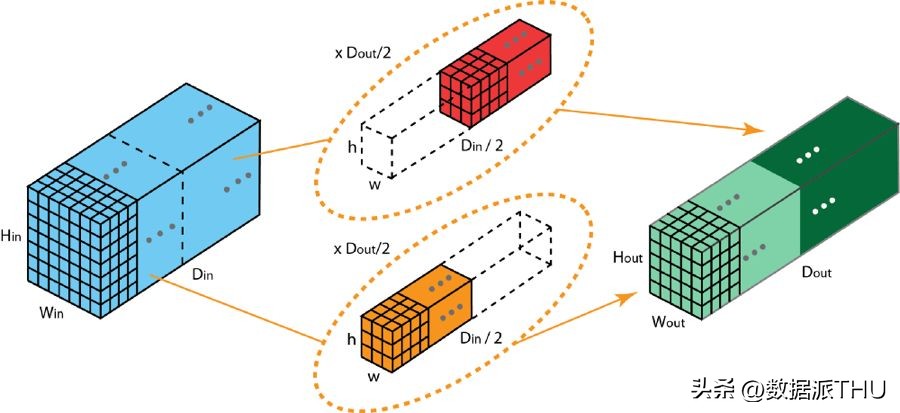
具有两个过滤器分组的分组卷积
上图呈现了包含两个过滤器分组的卷积结构。在这些分组中,每个过滤器的深度仅为2D卷积深度的一半开元棋官方正版下载,即Din/2。每个过滤器分组由Dout/2个过滤器组成。其中,第一个过滤器分组(以红色标示)对应于输入层的前半部分,即输入数据的前一半。
:, :, 0:Din/2
)卷积,而第二个过滤器分组(橙色)与输入层的后一半(
:, :, Din/2:Din
卷积操作导致每个过滤器分组产出Dout/2个通道。综合来看,两组过滤器合计生成2乘以Dout/2等于Dout个通道。随后,我们将这些通道叠加,最终形成拥有Dout个通道的输出层。
1、分组卷积与深度卷积
你或许会察觉到,分组卷积和深度可分卷积在运用深度卷积时,既存在某些相似之处,也存在若干不同点。当过滤器的分组数与输入层的通道数一致时,每个过滤器的深度便等于 Din/Din,即1。此时,过滤器的深度便与深度卷积中的深度相同了。
此外,目前每个分组均含有Dout/Din个过滤器。总体来看,输出层的深度达到了Dout。这一点与深度卷积有所不同——深度卷积并不会影响层的深度。而在深度可分卷积中,层的深度会在后续通过1×1卷积进行增加。
分组卷积有几个优点。
首先,其显著优势在于训练的高效性。这是由于卷积操作被分解为若干独立路径,每条路径均可独立由不同的GPU进行处理。因此,模型得以在多个GPU上实现并行训练。相较于在单一GPU上完成所有任务,这种在多GPU上实现的模型并行化使得网络在每一步骤能够处理更多的图像。普遍认为,模型并行化相较于数据并行化具有更高的优越性。将数据集划分为若干批次,并分别对每一批次进行独立训练。然而,若批次规模减小至极点,实际上便是在进行随机梯度下降而非批梯度下降。这种情况可能导致收敛速度减慢,甚至有时会导致收敛效果变差。
在深度训练神经网络的过程中,分组卷积扮演着至关重要的角色,就如同在ResNeXt架构中展现的那样。
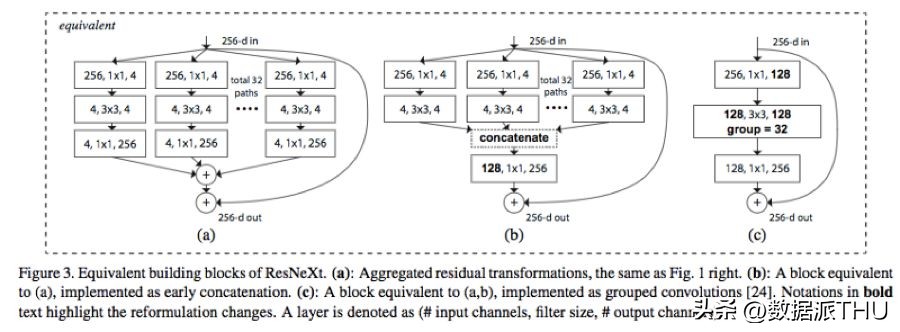
这幅图片摘自ResNeXt论文,该论文的链接为https://arxiv.org/abs/1611.05431。
第二个优势在于模型的运行效率将得到显著提升,具体表现为模型参数总量会随着过滤器分组数量的增加而相应减少。以先前的案例为例,一个完整的2D标准卷积层拥有h x w x Din x Dout个参数。而采用两个过滤器分组的分组卷积,其参数数量将变为(h x w x Din/2 x Dout/2) x 2个。由此可见,参数数量实现了减半。
第三个优势颇令人感到意外。分组卷积或许能够带来比传统完整二维卷积更为优越的模型效果。有篇出色的博客已经对此进行了详细阐述:
在https://blog.yani.io/filter-group-tutorial这篇教程中,我将对此进行简要概述。
原因与稀疏过滤器之间存在联系。图中展示了相邻层过滤器之间的关联性,这种关联呈现出稀疏的特点。

在 CIFAR10 数据集上训练的 Network-in-Network 模型中,相邻层的过滤器构成了一个相关性矩阵。在这个矩阵中,那些高度相关的过滤器呈现出较亮的颜色,而相关性较低的过滤器则相对较暗。该图片来源于:https://blog.yani.io/filter-group-tutorial。
分组矩阵的相关性映射图又如何?

在 CIFAR10 数据集上,一个 Network-in-Network 模型中的相邻层过滤器之间存在关联性。动态图详细呈现了分组数量分别为 1、2、4、8、16 的情况。相关信息可参考图片,链接为 https://blog.yani.io/filter-group-tutorial。
该图展示了在采用1、2、4、8、16个过滤器进行分组训练模型时,相邻层过滤器间的相互联系。文中提出了一种观点:过滤器分组的优势在于在通道维度上对块对角结构的稀疏性进行学习……在网络中,那些高度相关的过滤器是通过过滤器分组以更为有序的方式习得的。从实际效果来看,无需学习的过滤器关系便不再需要参数化。显著降低网络参数的规模,从而使得模型不易发生过拟合现象,因此,这种方法类似于正则化,使得优化器能够学习到更加精确和高效的深度学习模型。

正如作者所提及,AlexNet中的conv1层过滤器呈现了一种分组现象,这种分组似乎有意识地构建了两种不同的结构单元。这一分解模式可从AlexNet相关论文中的插图得到体现。
除此之外,每个过滤器分组都致力于掌握数据中特有的特征表示。正如 AlexNet 的创作者所阐述的,这些分组似乎会将所学的过滤器按照结构进行有序的划分,具体表现为黑白过滤器和彩色过滤器两大类别。
你认为深度学习领域的卷积还有那些值得注意的地方?


