卷积神经网络及其在图像处理中的应用

一,前言
深度学习方法的一种,专用于图像分类和识别开yunapp体育官网入口下载手机版,卷积神经网络是在多层神经网络发展而来的,这种网络结构经过特别设计,能够有效处理图像数据。多层神经网络的基本概念,需要先简单梳理一下。
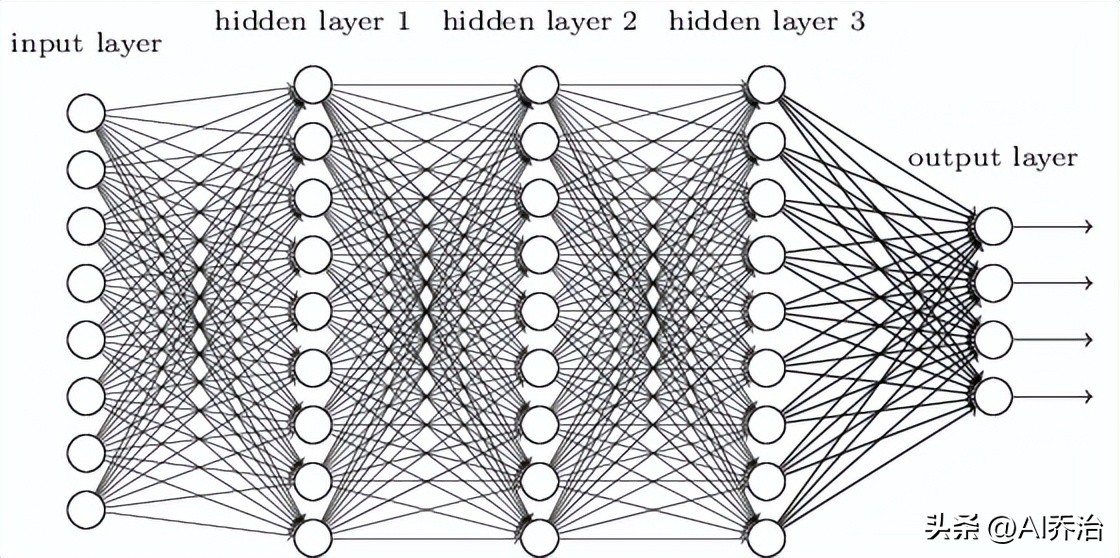
神经网络结构包含起始单元和终结单元,其间设有若干过渡单元。每个单元内分布着一定数量的基本处理单元,相邻单元的后续基本处理单元均与前一单元的各基本处理单元建立关联。针对常规的辨别任务,起始单元用以承载数据集,其内部各基本处理单元分别对应数据集的一个特定属性值。
图像识别任务里,输入单元每个可能对应一个像素的明暗程度,不过这种网络用于图像识别存在若干不足之处,其一它忽视了图像内部的空间布局,导致识别效果不理想,其二相邻单元间全部连接,参数数量庞大,使得训练过程缓慢。
卷积神经网络能够应对这些挑战,它拥有专门为图像识别设计的构造,因而训练过程十分高效,训练效率高让构建多层网络成为可能,而多层网络在提升识别精确度方面效果显著。
二,卷积神经网络的结构
卷积神经网络包含三个核心要素:局部感受区域,权重大同以及下采样处理。
局部感受区域:图像中的神经网络,其输入部分由单行神经元构成,而在卷积网络里,可将输入部分视为呈二维网格状分布的神经元单元
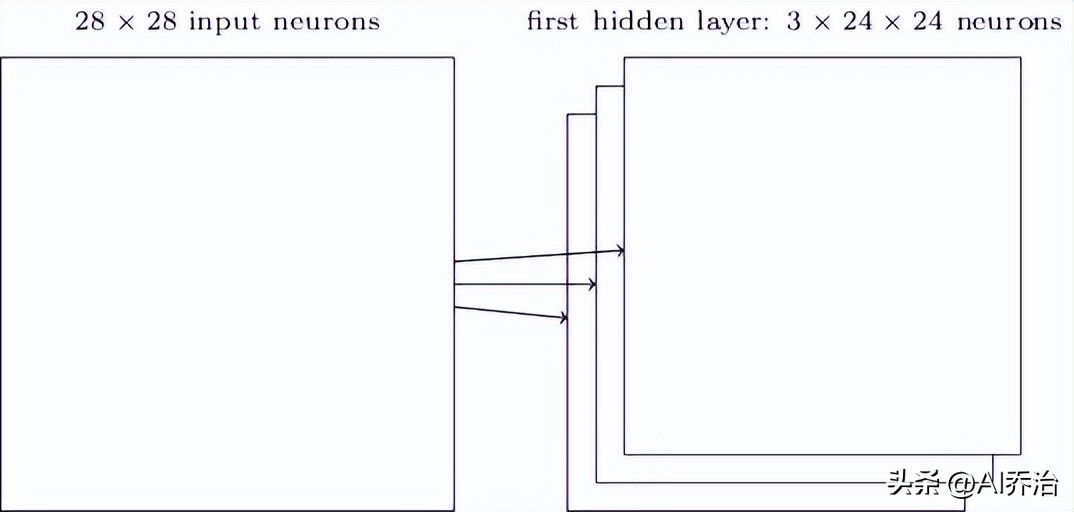
和一般神经网络类似,输入单元要和内部单元相连,不过并非每个输入单元都和每个内部单元建立联系,而是只在图像某个小范围内构建连接关系。比如一张28X28的图片,如果第一个内部单元关联输入层的一个5X5范围,其连接方式如图所示。
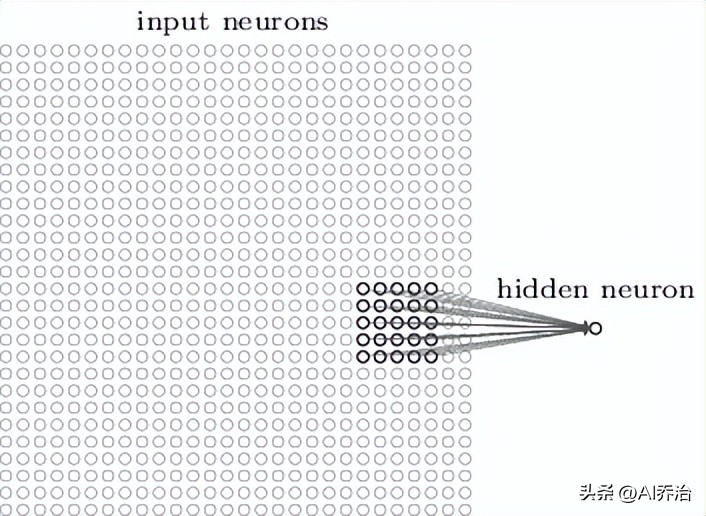
这个5X5的区域称作局部感受区域。此局部感受区域的25个神经元同第一个隐含层的一个神经元相接,每条连接均带有一个权重值,所以局部感受区域合计有5X5个权重。当将局部感受区域按照从左至右、从上到下的次序移动时,便可得到同隐含层中不同神经元的对应关系,下图分别呈现了第一个隐含层的前两个神经元同输入层神经元的连接图示。
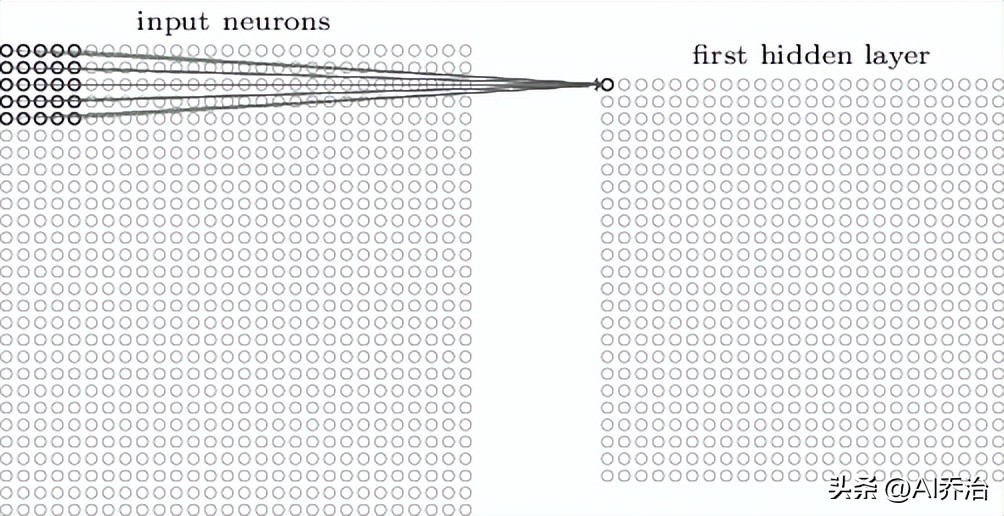
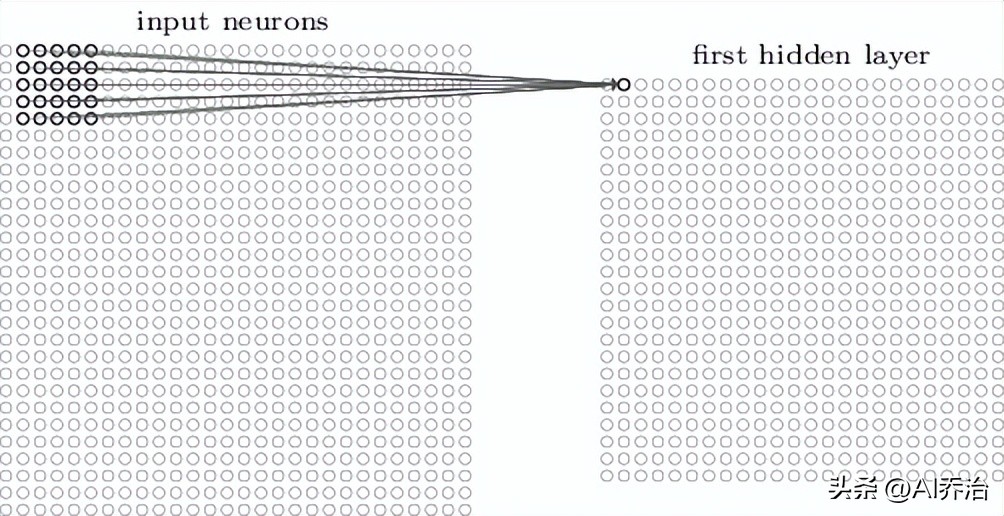
当输入端接收的是28厘米乘以28厘米的图形时,中间处理单元的检测区域宽高均为5厘米,经过初步处理后,该图形的尺寸会缩小为24厘米乘以24厘米。
共享权重:先前计算出的第一隐藏层全部24X24个神经元都采用相同的5X5个权重参数。第二个隐藏层中第个神经元的计算结果为:
这个是神经元所使用的激活函数开元ky888棋牌官方版,可能是sigmoid函数,或者是thanh函数,亦或是rectified linear unit函数。这个是感知域之间共用的偏差值。这个是一个5行5列的共享权重矩阵。所以总共有26个参数。这个是在输入层位置的输入激励值。
这表明初始隐藏层里每个神经元都在识别图像不同位置上的同一特征,所以这种从输入端到隐藏端的关系也被称作特征转换,这种特征转换所用的权值是共用的,其偏置也是共用的。
进行图像识别工作时,往往需要多种特征转换,所以一个完整的卷积单元会集成多个独立的特征转换通道。参照下图,展示了包含三个特征转换通道的构造。
实际运用里,卷积神经网络或许会运用到数十个特征映射,以MNIST手写数字识别为例,其习得的部分特征有:

这二十张图画各自对应一个不同的特征映射,或者也可以称作是过滤器或核心。每一个特征映射用五乘五的图画来表现,它象征了局部感知区域里的五乘五组权重值。发光的点子意味着较小的权重,而它们在图画中所产生的效果也相对轻微。相反,发暗的点子则表示较大的权重,这表明它们在图画中对应位置的影响力更强。可以感知到这些特征映射揭示出特定的空间构造,因此卷积神经网络掌握了部分与构造相关的知识来执行识别。
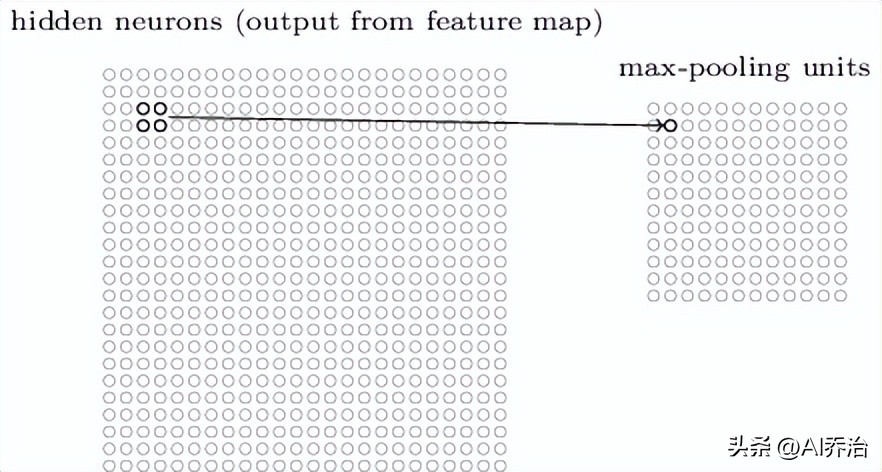
池化层通常跟在卷积层后面,它的作用是简化卷积层的输出结果。比如,池化层中的每个神经元可能会把前一层的一个2X2区域内的神经元数值加起来。还有另一种常用的池化方式,叫做最大池化,这种方式会直接把一个2X2的输入区域里的最大数值作为输出结果,具体可以参考下图。
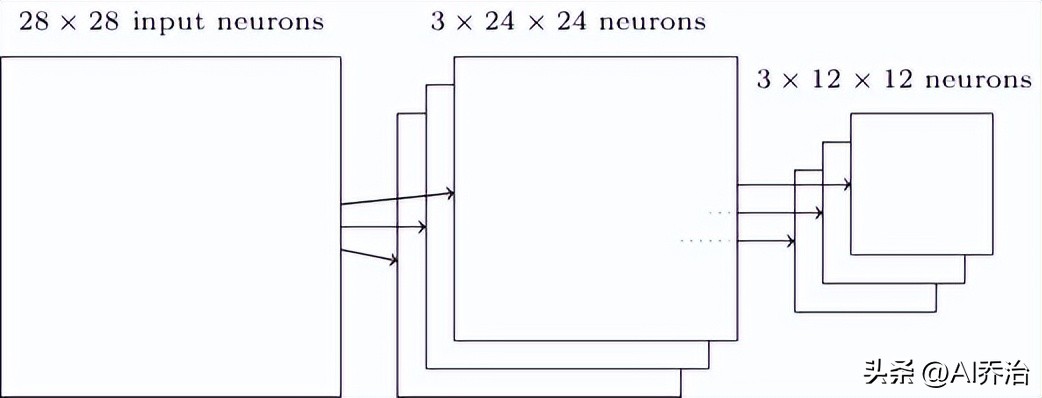
卷积层的结果由24X24个神经元组成,经过池化处理后,数量会减少到12X12个神经元。每个特征图都要进行独立的池化操作,之前描述的卷积层和池化组合的结构是这样的:
池化操作并非唯一选择,存在另一种池化技术,该技术计算卷积区域中神经元输出的平方和再开平方根。虽然具体实现与最大池化不同,但同样作用是简化卷积层输出的信息。
把前述部分组合起来,再添设一个输出单元,便构成一个完整的卷积型神经网络体系。在辨识手写数字的应用场景里,那个输出单元设有十个处理单元,各自负责生成0到9的判定结果。
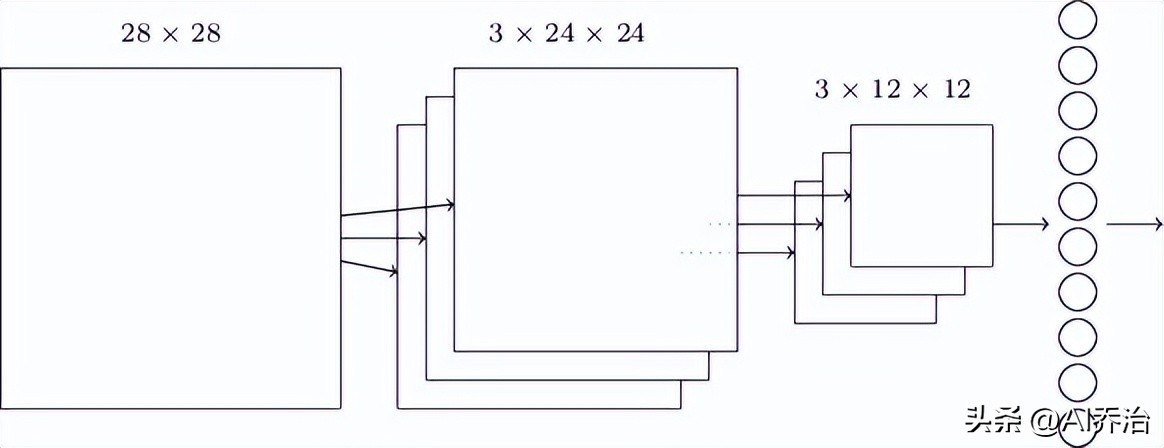
网络最底层是一个全连接层级,这一层里每个神经元都和上一个最大池化层的所有神经元建立了联系。
这种构造在具体应用中是一种特殊情形,常规的卷积神经网络设计里,通常在卷积运算单元和下采样环节之后,也能够增设一个或若干个全矩阵连接单元。
三,卷积神经网络的应用
3.1 手写数字识别
Michael Nielsen撰写了一本关于深度学习和卷积神经网络的网络电子书,还附带了一个手写数字识别的示范程序,这个程序能够从GitHub上获取。这个方案基于Python和Numpy, 能够便捷地构建多种形态的卷积神经网络来识别手写数字, 同时借助名为Theano的机器学习框架执行反向传播运算和随机梯度下降优化, 以此确定神经网络的各项系数。Theano支持在图形处理器上执行, 故能显著减少模型训练所需周期。CNN的代码在network3.py文件中。
作为初始示范,可以尝试构建一个仅含单隐层的网络,具体实现代码如下:
>>> import network3
从名为network3的模块中导入Network这个类
从网络3模块中导入卷积池化层,完全连接层,以及软最大层
训练数据, 验证数据, 测试数据 = 网络3 加载共享数据
>>> mini_batch_size = 10
>>> net = Network([
全连接层输入维度为784, 输出维度为100,
Softmax层参数数量为输入100输出10的配置完成,接着确定小批量数据量大小
网络使用随机梯度下降法优化训练数据,迭代周期为六十次,每个小批次包含指定数量的样本,学习率设定为点一,
validation_data, test_data)这个网络包含784个输入单元,其隐藏部分有100个单元,而输出部分则设有10个单元。当运用测试数据集进行评估时,该网络实现了97.80%的正确识别率。
能否通过运用卷积神经网络来获得更佳的成效呢?可以尝试构建一个网络架构,该架构包含一个卷积单元,一个池化单元,以及一个附加的全连接单元,其具体形态展示于下图
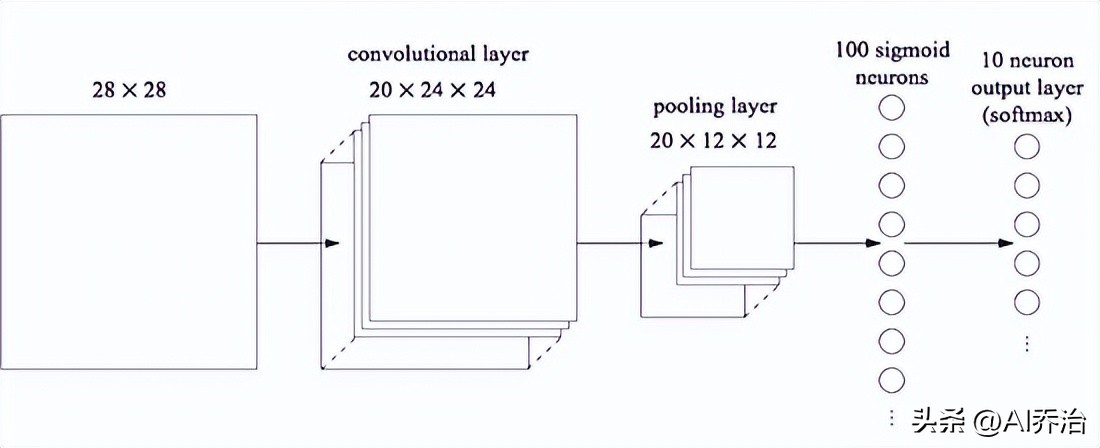
这种构造方式可以这样领会:卷积层和池化层旨在掌握输入图像的局部布局特征,而紧随其后的全连接层则致力于在更为宏观的维度上进行分析,它能够综合整个图像所蕴含的更为广泛的整体信息。
>>> net = Network([
图像的形状为 mini_batch_size, 1, 28, 28, 这一层的结构包括卷积和池化操作
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
全连接层输入维度为20乘以12乘以12个节点,输出维度为100个节点,
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)该卷积神经网络模型的识别精确度达到98.78%。若要继续提升精确度,可从以下途径着手:
再添加一个或多个卷积-池化层
再添加一个或多个全连接层
可以选用其他激励函数来替换sigmoid函数,例如Rectified Linear Units函数,该函数相较于sigmoid函数,能够加快训练进程。
扩充训练资料库。深度学习由于参数众多,必须依赖丰富的训练资料,倘若训练资料匮乏,或许难以构建出功能完备的神经网络。惯常方法是在既有训练资料的基础上,借助特定算法生成大量相似数据以供训练之用。譬如,可将每幅图像沿水平或垂直方向位移一个像素单位,具体包括向上、向下、向左及向右四种平移方式。
通过多个网络组合实现,构建多个结构一致的神经网络,参数采用随机设置,训练完成后用它们的输出进行投票,从而确定最优分类结果。实际上这种集成方式并非神经网络专属,其他机器学习技术也运用此方法增强算法的稳定性,例如随机森林。
3.2 ImageNet图像分类
Alex Krizhevsky及其团队在2012年发表的论文《使用深度卷积神经网络对ImageNet的一个子集进行识别》中,针对ImageNet的部分数据实施了分类工作。ImageNet总共收录了1500万张带标签的高清照片,涵盖了22,000个类别。这些照片通过网络收集,并且经过人工标注。自2010年起,ImageNet举办了一个图像识别比赛,名为ILSVRC,即ImageNet大规模视觉识别挑战赛。ILSVRC选用了ImageNet里的1000类图片,每类大约有1000张图。总共包含120万张用于训练的图,还有5万张用作验证的图和15万张用于测试的图。文中提出的方法错误率为15.3%,相比之下,第二好的方法错误率达到了26.2%。
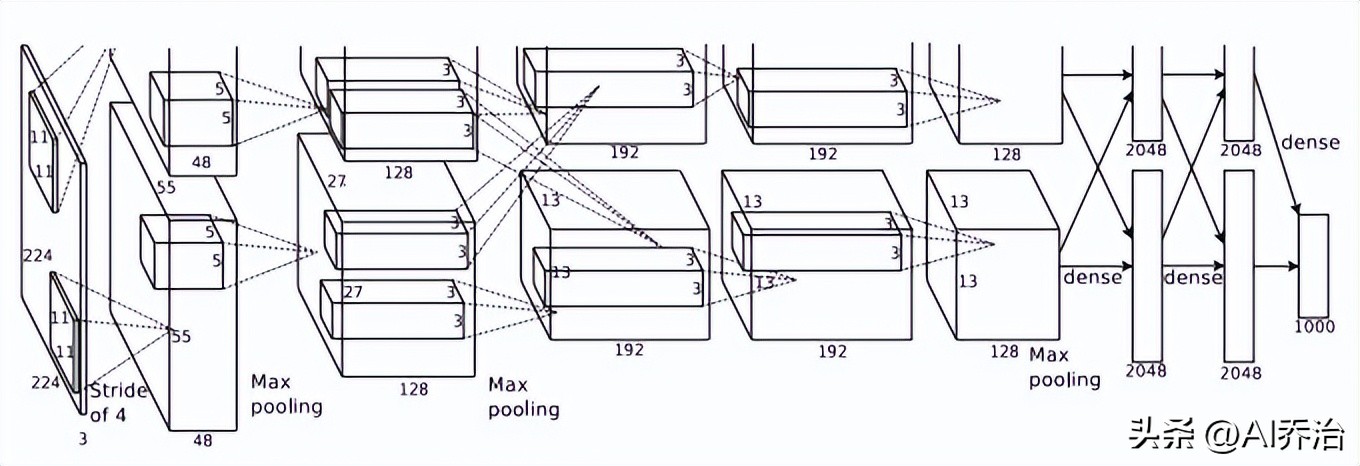
这篇文章总共设有七个隐含层级,其中前五个为卷积层级,部分层级应用了最大池化操作,后两个层级则采用全连接层级。最终的输出层级是一个包含一千个单元的softmax层级,这一层级与一千种图像类别相对应。
这个神经网络借助GPU来运算,不过单个显卡的存储空间有限,因此必须配备两块GPU(GTX 580,每块拥有3GB显存)才能顺利开展训练工作。
这篇文章为了防止模型过度拟合,使用了两种策略。第一种是人工创造更多训练样本,比如对现有图像进行平移或水平反转,通过主成分分析调整RGB通道数值等。这种做法使训练数据量增加了2048倍。第二种是应用Dropout技术,该技术会随机将隐藏层中一半神经元的输出强制设为0。通过这种方法可以加快训练速度,也可以使结果更稳定。

输入图像的尺寸为224乘以224乘以3,感知区域的尺寸为11乘以11乘以3。图中展示了第一层训练出的96个卷积核。其中前48个卷积核是在第一个GPU上训练完成的,后48个卷积核则是在第二个GPU上训练完成的。
3.3 医学图像分割
Adhish Prasoon及其团队在2013年发表的论文《采用三平面卷积神经网络进行深度特征学习以分割膝关节软骨的MRI图像》中,运用卷积神经网络技术对膝关节软骨进行分割。常规卷积神经网络是平面架构的,若将其拓展为立体形态,会显著增加参数数量,导致网络结构更为繁复,同时延长训练周期并提升对训练资料的需求量。但若仅采用平面数据,则无法充分运用立体信息,或会降低识别成效。针对此问题,Adhish提出了一种平衡策略:构建三个基于二维平面的卷积神经网络,并将它们的输出结果进行整合。
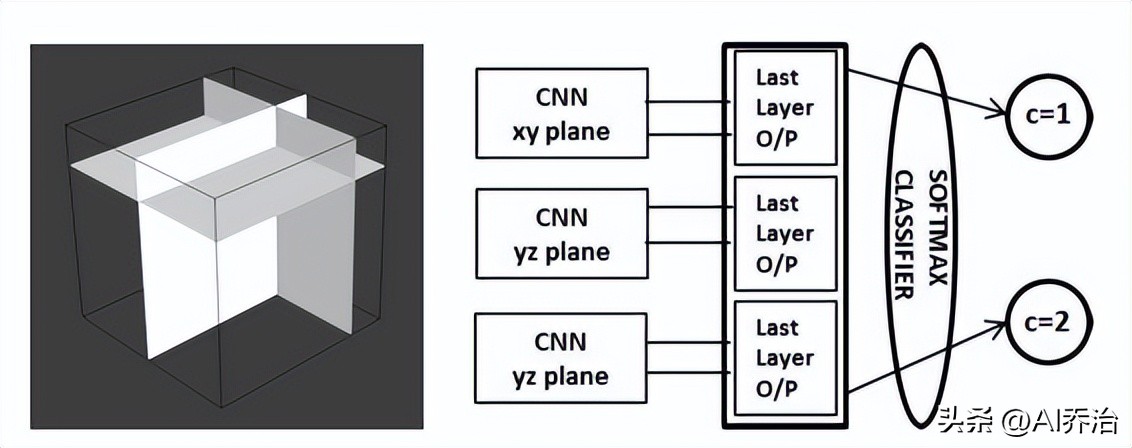
三个二维卷积神经网络各自承担对平面和进行解析的任务,它们的解析结果汇集到一个概率分布转换层,由此形成最终的预测结果。这项研究以25名患者的医学影像作为学习素材,从每个立体图像中提取4800个空间数据点,总共获得了12万个学习数据点。与以往需要人工从立体照片中挑选特征进行区域划分的技术不同,这种办法在准确度上有了显著进步,同时减少了学习周期。
3.4 谷歌围棋AlphaGo战胜人类
谷歌的DeepMind团队借助深度卷积神经网络,在电脑围棋领域实现了显著进展。先前,IBM的深蓝超级计算机凭借卓越的计算性能,借助完全列举法击败了人类顶尖象棋选手,然而这种胜利并非真正的“智能”。
围棋的推演难度远胜象棋开yun体育官网入口登录app,即便借助最顶尖的机器也无法遍数所有潜在的下法。围棋的推演是个异常棘手的事务,其难度比国际象棋要大得多。围棋最多种局式达到3的361次方,其大致规模约为10的170次方,而当前观测到的宇宙内,原子的总数不过10的80次方。国际象棋最多只有2的155次方种局式,即香农数,其大致数值为10的47次方。
AlphaGo通过卷积神经网络掌握人类围棋技艺,最终获得重大进展。AlphaGo在与欧洲冠军樊麾的比赛中,不带让子条件以5:0全胜。研究者还让AlphaGo与其他围棋AI进行对抗,总共进行495场,仅输掉一场,胜率达到99.8%。它还曾与Crazy Stone、Zen以及Pachi这三个顶尖AI进行4子对决,赢得的比率分别是77%,86%和99%,由此可以看出AlphaGo实力超群。
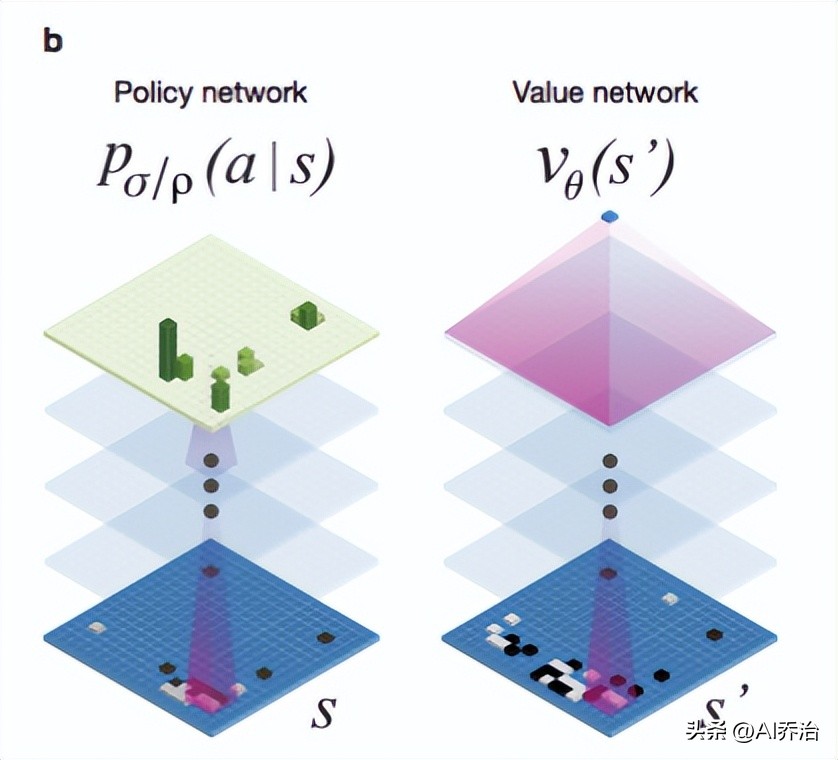
谷歌团队的研究文档里说明,他们借助19X19的图形来标示棋盘上的点,以此对两种不同的深度学习网络进行培育,这两种网络分别是“策略网络”和“值网络”。它们需要协同筛选出有潜力的着法,舍弃显而易见的劣着,以此确保运算负担在机器处理能力之内,这种做法与人类棋手的思路基本一致。
在算法中,“价值函数”用于降低探索的层级,当AI进行推演时,若发现当前状态处于明显不利,则会立即舍弃部分路径,避免沿着单一方向持续计算;而“策略函数”则用于缩小分析的广度,对于棋局中的某些落子选择,有些显然是不恰当的,例如不应轻易让棋子被对方吃掉。借助随机模拟方法,将相关数据代入概率模型,人工智能便无需对每一步都同等对待,而是能够着重考察那些具备潜力的走法。
为了方便众多关注人工智能的朋友深入学习,并开展相关论文研究,我们精心准备了一套人工智能学习资源分享给大家,收集资料耗费了大量时间,内容十分丰富。
包含人工智能基础入门视频和文档,还有AI常用框架实战视频,涉及计算机视觉,机器学习,图像识别,自然语言处理,OpenCV,YOLO,pytorch,深度学习与神经网络等学习内容,提供课件源码,汇集国内外知名精华资源,以及AI热门论文等完整学习材料。
想要获取这些资料,请先关注作者在头条上的账号【AI乔治】。然后回复【666】,就能免费得到这些内容。
每篇专栏都聚焦深受关注且富有意义的议题,倘若我的文字能为你带来裨益,恳请你动动手指点赞、评价、分享,你的鼓励将促使我创作出更优质的内容,在此深表谢意!





