卷积神经网络新手指南之二
卷积神经网络新手指南之二
引言
本文将深入分析卷积神经网络的若干方面,注意:文中部分论述较为艰深,为确保表述清晰,相关文献的详尽阐述会置于文末标注。
步幅和填充
回顾先前的转换层级,在起始段落曾提及过滤器及接收区域。如今,我们能够借助调整两个核心要素来规范每一层的表现。选定过滤器尺度后,同样需要确定“间隔”与“留白”。
过滤器卷积过程受步距影响。先前章节曾举例说明,过滤器围绕输入数据移动时,每次沿一个方向跨越一个数据点。过滤器整体移动的距离就是步距。步距一般通过特定算法设定,目的是确保最终输出结果为完整数值,避免出现小数部分。让我们设想一个场景,假设有一个7行7列的输入矩阵,配备一个3行3列的滤波器,暂且不计其第三维度,同时设定步长为1,这就是我们通常所见的配置。
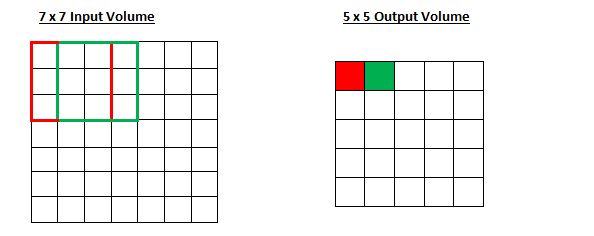
是否与先前一致?你能够继续推测,倘若步长增至二,结果值会如何变化。
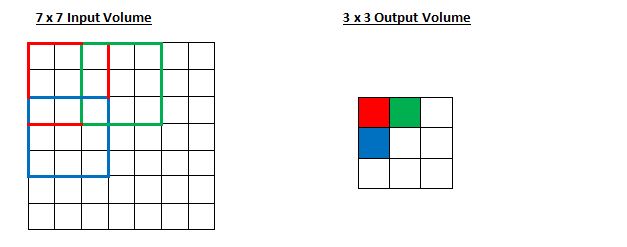
所以,显而易见,接收区域正以每步两个单位行进,伴随输出量相应降低。留意,倘若我们打算把步长设定为三个单位,那么在处理间隔距离以及保障接收区域所需输入数据量这两方面,就会引发矛盾。一般情况下,当开发人员期望接收区域彼此交叠的程度更低且空间范围更小时,他们倾向于调大步长。
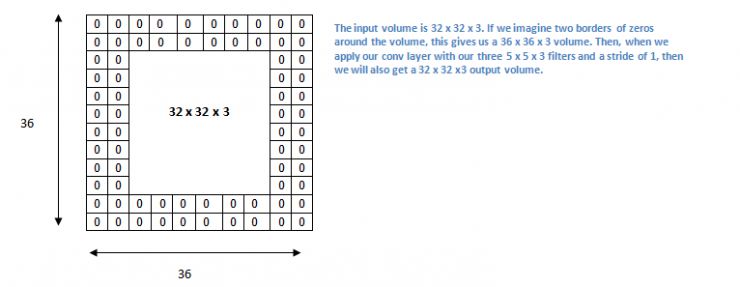
现在让我们继续探讨填充,在正式展开讨论之前,需要构思一个实例。设想一下,假如把三个5×5×3的卷积核处理到一个32×32×3的数据块上,最终会形成怎样的结果?
空间维数会缩小,连续使用卷积层后,体积的减小速度超出预期。神经网络的初始阶段,需要尽可能保留原始输入数据,以便提取基础特征。我们希望重复应用卷积层,同时确保输出尺寸维持在32 x 32 x 3。要实现这一点,我们可以对该层施加宽度为二的零值填充。这种零值填充会在输入数据的边缘加入数值为零的部分。以宽度为二的零值填充为例,它会使一个36×36×3的输入数据扩展。
如果步长为1,并且将零填充的尺寸设定为
K是过滤器大小,输入和输出量将会一直保持同样的空间维度
对于任何给定的卷积层输出大小的计算公式
O是输出大小,K是过滤器大小,P是填充,S是步幅。
选择超参数
我们如何判断应该设置多少层级、多少个卷积单元、核的尺寸是多少,又或者步长和填充应该取什么数值?这些问题都至关重要,但至今没有一套被所有研究者普遍遵循的规范。这主要是因为神经网络的性能很大程度上受到数据特性的影响。数据的规模差异悬殊,这源于图像本身的复杂程度、图像处理任务的不同要求以及其他诸多因素。审视个人数据时,确定最优参数的一种途径是,识别出能产生恰当视觉简化效果的合理区间,并找到其中的正确搭配方式。
修正线性单元(ReLU)层
卷积层处理完成后,通常紧随其后会设置一个非线性层,也称作激活层。该层的主要作用是为系统引入非线性特性,其基本功能是在卷积层执行线性运算(即元素的相乘和求和)。以往多采用tanh或sigmoid这类线性算法,但研究人员发现ReLU层表现更优,原因在于它显著提升了网络训练的效率(得益于计算优势),同时模型的精确度并未出现明显下降。它也能减轻梯度消失的现象,原因是网络在训练时低层参数更新速度很慢,梯度在经过各层后呈指数级衰减,ReLU单元使用的函数f(x)= max(0,x),该函数将所有负输入转化为零值,这一层增强了模型的非线性表达,同时整体上不改变卷积层的感受野范围。对深入研究感兴趣的人可以查阅深度学习奠基人Geoffrey Hinton的作品Geoffrey Hinton, 他撰写了相关论文
池化层(Pooling Layers)
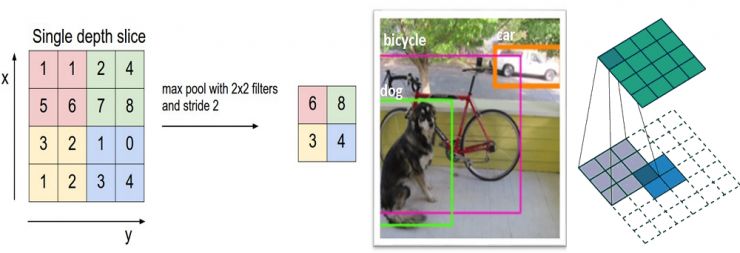
经过多个激活函数处理后,开发人员能够选用池化单元,该单元也称作降维单元。此类单元存在多种形态,不过最大池化单元最为常用。它需要设定一个规格为2x2的窗口,并且采取相同的移动距离,接着对卷积区域中每个分组的输入数据和输出数据实施最大值提取操作。
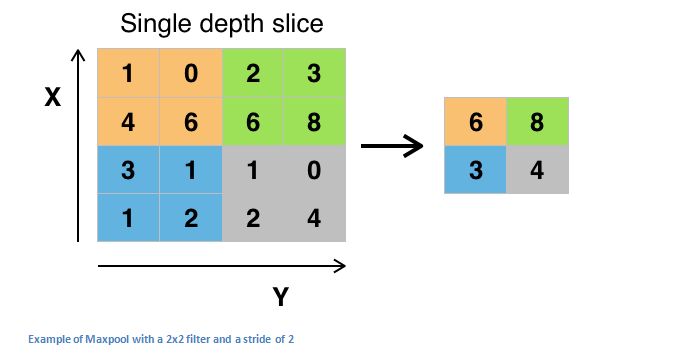
池化层还有其他类型,比如均值池化和L2范数池化。之所以采用这类层,是因为一旦确定某个特征是原始输入中的显著部分(会伴随高激活值),那么这个特征在空间上的精确位置并不关键。可以设想开元ky888棋牌官网版,这一层显著压缩了输入数据的平面尺寸,即长和宽发生改变,而高度保持不变。这样做主要有两个意图,其一,参数或权重的数量削减了四分之三,进而减小了运算开销。其二,这种方式有助于防止模型发生过度学习。这种状况指的是,当模型对训练样本过度适配时,它将无法有效泛化到验证和测试数据上。一种模型的特性表现为,它能够完美匹配全部训练样本,却仅对一半的测试样本有效。
降层(Dropout Layers)
降层在神经网络里具备一个很独特的效用。先前章节里,我们探讨了过度拟合的现象。经过训练后,网络参数会适配特定的训练数据,因此面对新的输入时,其运行效果会欠佳。这个概念在自然界中过于简单化。
丢弃层在传播期间将部分激活值清零,随机舍弃部分信息,原理非常直接。这种方式有什么优势呢?它促使网络结构变得更为精简。即便部分激活信号被移除,神经网络依然能够准确识别样本,给出正确分类或输出结果。它保证网络不会过分适配训练数据开yun体育app入口登录,这样可有效减轻过度拟合状况。这一层关键之处在于只在训练时启用,测试时则不用。
网络层网络
网络层网络是一种采用1 x 1尺寸过滤器的卷积层。初看之下,人们或许会疑惑此类层为何有效,毕竟输入区域的规模往往超过其映射区域。但需留意,这些1x1卷积具备特定深度,因此可视作1 x 1 x N的卷积形式,N代表该层中过滤器实施的总次数。这个层级本质上是在执行多维元素的逐项相乘操作,其中维度的数量取决于输入数据的层级深度。
分类,定位,检测,分割
本节借助先前提及的案例开元棋官方正版下载,探讨图像分类工作。图像分类工作涉及识别输入图像并判定其属于何种图像类别,然而若将目标定位作为任务,则工作不仅需要给出分类标签,还需确定目标在图像中的具体位置。

也存在识别物体的情况,需要找出图中所有物体的准确位置。这样一来,图像内部会出现许多框线,并且配有各种标记。
最后,存在一项关于识别特定类别的任务,这项任务要求标注出图像中所有该类别对象的边界线。

迁移学习(Transfer Learning)
深度学习领域里普遍存在一个误区,认为没有像谷歌那样庞大的数据基础,就无法构建出性能良好的神经网络,尽管数据对神经网络构建至关重要,但迁移学习的方法能够有效降低对数据量的依赖。迁移学习是将一个先前训练好的模型,其网络权重和参数已通过大规模数据集或他人训练,再利用自己的数据集进行“微调”的方法。这种思路是让预先训练的模型充当特征提取器,移除网络末端层,并换成适合您问题领域的分类器。接下来,将剩余各层的参数固定住,然后对网络进行常规训练,固定参数的作用是让它们在梯度下降或优化环节保持不变。
让我们弄明白这种方式为何有效,比如在ImageNet这个包含1400万张图像、涵盖1000多个类别的数据集上预先训练的模型。当我们审视网络的底层时,可以发现它们擅长识别边缘和曲线这类特征。除非你面对的问题领域和数据集非常特殊,否则你的网络同样需要能够捕捉到曲线和边缘。通过随机设置权重来训练全部网络,不如采用已训练(且固定)的模型权重,集中精力处理更关键(层级更高)的部分进行训练。当你的数据集与ImageNet等差异极大时,需要加强你的层,同时固定一些基础层级。
PS : 本文由雷锋网独家编译,未经许可拒绝转载!
via Adit Deshpande




