应用丰富的“卷积神经网络”技术,怎样实现了图像识别?
图像识别是门引人入胜,却极富难度的学科分支。文章将借助卷积神经网络,阐释图像识别的内涵、实践以及具体实施手段。
什么是“图像识别”?它的作用是什么?
从视觉技术层面讲,“图像识别”指的是软件能够分辨图像中的人、地点、物件、行为以及文字的这种功能。计算机借助视觉技术手段,融合人工智能程序与摄像头,即可达成图像识别的目标。
对于人类大脑以及动物大脑而言,辨认物体十分容易;然而对计算机而言,这项任务却异常复杂。人类观察一棵树木、一辆汽车,或是一位熟人时,能迅速识别出对象,完全无需有意识地探究和琢磨。
不过对计算设备而言,分辨某个物件(或许是个计时工具、件家具、位人物或种生物)相当棘手,并且探寻此道途充满相当大的变数。
图片: CS231.github
图像识别属于机器学习范畴,其核心是模拟人脑的运作机制。借助图像识别技术,电脑可以辨识出图像里的各种物体和构成成分。凭借海量的数据资料以及创新的分析模式,电脑能够解读图像内容,并运用数学方法标明其对应的标记和归类。
图像识别的普遍应用
图像识别用途极多,其中“个人影像归类”最为普遍,也最受青睐。面对成千上万张杂乱的照片,几乎每个人都要按照片内容把它们分开,组成条理清晰的照片库。
当前,那些用来整理照片的程序正在应用“影像辨识”技术,它们不仅为用户准备相片的存放位置,还打算借助“影像自动整理”,为人们带来更高效的相片检索服务,程序里的影像辨识编程通道可以按照不同的辨识样式对影像进行归类,并且依照专题将它们一一聚集在一起。
图像识别的其它用途还包括,照片及视频平台,互动式宣传,创新性活动,社交平台中的人脸和图像辨认,还有海量数据环境下的网络图片归类。
图像识别是一项相当困难的任务
图像识别工作难度很大,有效途径之一是借助元数据来处理非结构化信息。让人类专家负责人工识别音乐库和影像库的工作,看起来相当困难,但更难实现的目标是——训练自动驾驶汽车的路径规划程序去分辨路上的行人以及各种交通工具,或者让该程序处理社交平台上出现的大量视频和图片,完成筛选归类和打标工作。
处理该问题的途径之一涉及神经网络技术,从理论层面看,能够借助卷积神经网络解析图像数据;然而从运算成本角度审视,这种方式存在显著缺点。譬如,即便针对面积仅30*30像素的图像进行处理的卷积神经网络,其内部参数数量仍高达五十万,同时需要九百个输入单元参与运算。一种性能比较突出的设备能够应对此类画面,然而当画面规模提升时,例如要处理500*500像素的图形,那么配套的参数与数据输入量将急剧攀升,这台设备可能就难以胜任了。
神经网络在图像识别中的另一弊端在于:过度匹配。具体而言,若一个系统对自己所接触的学习资料进行过细的适配,就会产生“过度匹配”现象。“过度匹配”会引发参数数量激增,从而加大运算负担,并且当该系统面对新的信息进行学习时,其整体表现会随之下降。
卷积神经网络
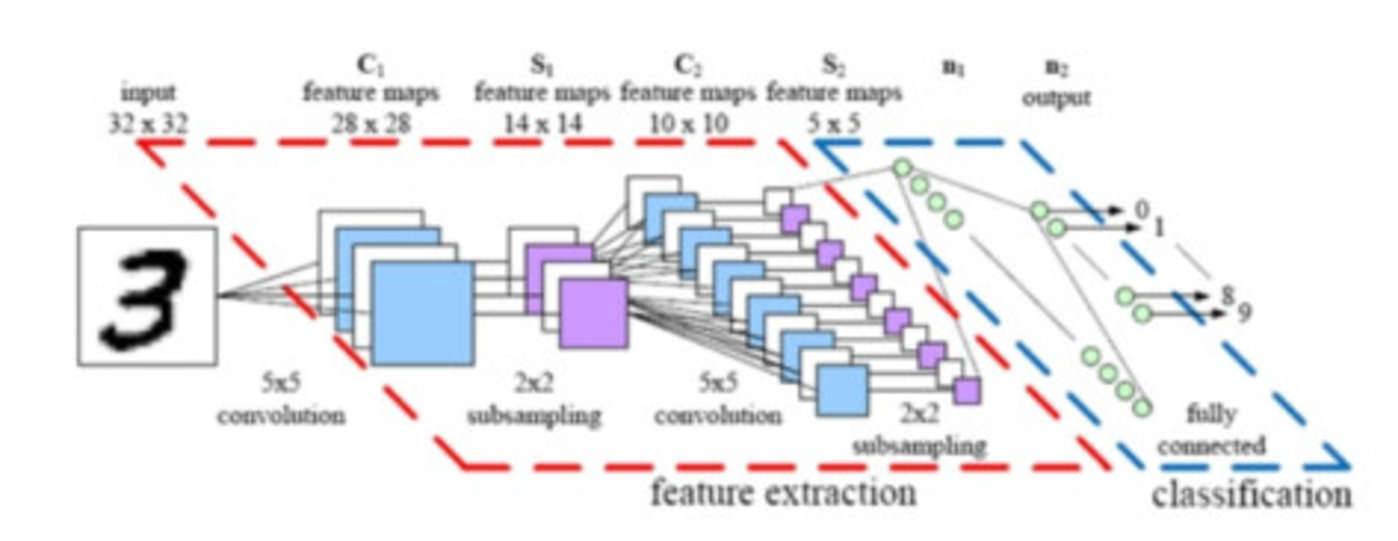
卷积神经网络架构模型(图片: Parse)
针对神经网络构造,稍加调整就能使处理大幅图像更为便捷,由此便形成了我们所说的“卷积神经网络”,它也被称为CNNs或ConvNets。
神经网络通用性强是它的一个优点,不过,在应对图像数据时,这个优点反而成了阻碍。这种卷积神经网络有目的地进行了取舍:假如某个网络是专门用来分析图像的,那么为了获得更实际的效果,就必须放弃部分其通用的能力。
图像之间的邻近程度和相似程度相互关联,卷积神经网络正是借助了这种关联。具体来说,某一图像内邻近的像素点,其关联性要强于相隔较远的像素点。然而,传统神经网络中所有像素点都与所有神经元存在连接。这种连接方式会导致计算量剧增,从而影响网络的整体精确度。
卷积神经网络处理此问题的方法,是移除那些非必要的连接关系。从技术角度分析,卷积神经网络依据相邻元素的关联性,对连接进行筛选和过滤,从而使得图像处理在计算上更为高效。
在指定的层级里,深度学习的卷积构造并非将全部数据与所有节点建立关联,而是刻意约束这些联系,使得任何一个节点仅能获取该层级中极少数的数据输入,换句话说,网络中的每个节点只负责分析图像中的某个局部区域。这种运作模式同我们大脑皮层神经元的机制极为接近,因为大脑中的每一个神经元仅会对视觉感知中的某个极小片段产生应答。
“卷积神经网络”的处理流程
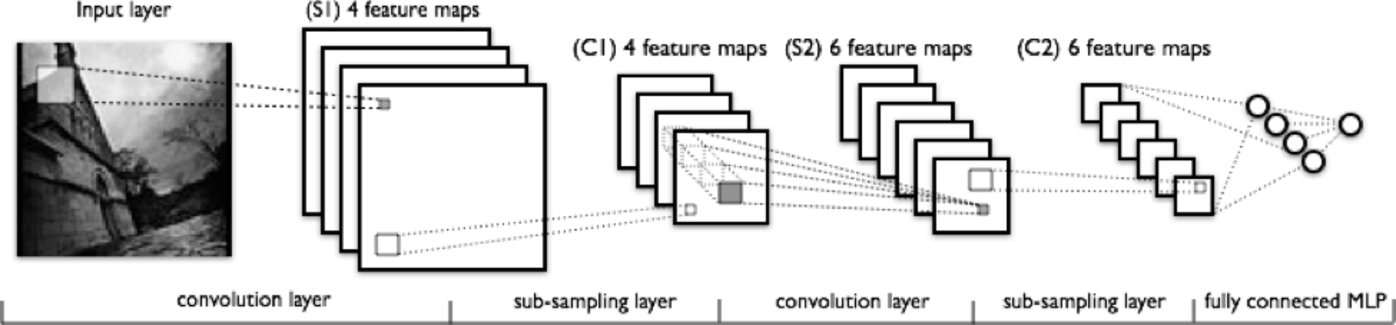
图片: deeplearning4j
从左到右观察上图,你会发现:
图像需要实施特征提取操作,图中颜色较浅的方框即为执行特征提取的过滤器,
叠加形成的“激活映射”逐层堆叠开元ky888棋牌官网版,每层对应一个滤波器,尺寸较大的矩形区域将在下一轮处理中进行缩小处理。
“激活映射”通过下采样,被不断地压缩。
让滤波器穿过“激活映射”层叠中的每一层,就会得到一系列全新的“激活映射”,这一系列“激活映射”接下来都要进行下采样处理。
第二次下采样会压缩新的“激活映射”。
一个全连接的层指定了每个节点的输出为一个标签。
一种深度学习模型怎样借助邻近关系来筛选连接呢?关键在于两种创新的结构:下采样层和特征提取层。下面,我们以某个网络模型为例,逐步剖析其筛选过程。
第一步是卷积层,而卷积层本身也包含了几个步骤。
首先,我们把一张照片分解成一系列重叠着的3*3像素块。
接下来,我们维持权重恒定,把各个像素块放到一个简单的单层神经网络里处理。这样做,这一系列像素块就会转换成一个数组。由于图像已经被分解成很小的像素块(在这个例子中是3*3的像素块),因此神经网络的运算就变得容易许多。
随后,数值将被组织进一个列表里,里面每个数对应图像不同部分的信息,横纵坐标分别对应色彩、尺寸和高度。所以,这个情境下会形成一个三维的九宫格数据。(假如是动态影像,那么这些数据将扩展为四维结构。)
接下来是池化层,它对三维或四维的数组进行池化处理,并将下采样功能与空间维度相结合使用。经过这样的操作,我们可以得到一个仅包含关键图像信息的池化数组,因为这个数组去除了冗余的图像内容,仅保留了相对重要的部分,因此网络的计算压力得以减轻,同时有效防止了过度拟合现象的发生。
这个经过降维处理的数组将作为标准全连接神经网络的输入数据,由于我们已通过池化与卷积显著减小了输入规模,因此现在需要一种普通网络能够处理的、且能保留核心信息的数据形式,最终输出结果将用于评估系统对图像判定的置信程度。
实际运用中,深度神经网络的结构错综复杂,其中包含大量隐含单元、下采样单元以及特征提取单元。同时,标准型深度神经网络往往配备有数以万计的标记数据。
如何建立一个卷积神经网络?
构建一个卷积神经网络成本很高,而且费时很长,科技企业推出的应用程序,是为了帮助那些没有内部人工智能技术人才或图像识别技术人才的机构,也能实现目标。
Google Cloud Vision
谷歌云视觉是谷歌推出的图像识别服务。该服务依托开源TensorFlow平台构建,采用REST接口进行调用。它拥有丰富的标签信息库,可以识别出人脸和物体特征。
IBM Watson视觉识别
“IBM Watson视觉识别”归属于“Watson开发云”体系,拥有一个规模宏大的预设分类库,可以针对用户指定的图像来训练个性化的类别。此外,它还具备多种先进技术开yun体育官网入口登录app,诸如对不适宜内容的识别,以及对文字信息的自动提取。
Clarif.ai
Clarif.ai是一款创新的视觉分析平台,它采用RESTful接口进行交互。该平台配备了参数配置单元,这些单元支持针对特定领域进行算法优化,例如餐饮、观光或婚庆等专项内容。
一般情形下,该API尚可使用,但为特定任务,设计专属方案更为理想。当前众多数据集,能助开发与数据科学家集中精力训练模型,无需过多操心网络调优和运算难题,从而让工作变得轻松许多。
卷积神经网络的一个有趣应用
给无声电影自动配音
要适配一个无声影像,系统需在该影像中添加音频开元棋官方正版下载,这个系统借助成千上万部视频进行学习,这些视频里展示了鼓棒敲打不同物体时产生的各种声响,一个深度学习机制将影像的每一帧与一个已存的声音集合进行比对,从而确定哪个声音最契合影像中的场景
接下来,该系统将由一个检测设备进行检验,这个检测设备同人类用来分辨真实嗓音或人造声音(合成音)的工具极为相似。这确实是一个十分独特、颇为有趣的卷积神经网络与LSTM递归神经网络的应用。请参考下方的视频内容。




