一文读懂遗传算法工作原理(附Python实现)

机器之心编译
参与:晏奇、黄小天
最近Analyticsvidhya网站发布了一篇标题为《遗传算法入门及其在数据科学中的应用》的文章,作者Shubham Jain通过自身经历,用浅显易懂的表述对遗传算法进行了系统而精炼的介绍,同时展示了该算法在不同领域的实际运用情况,特别强调了遗传算法在数据科学领域的具体实施方法。
简介
日前,我开始着手处理一个具体难题——大型商场的销售状况问题。运用了几个基础模型,并完成了一些特征加工,随后我在排名榜上位列第 219 位。
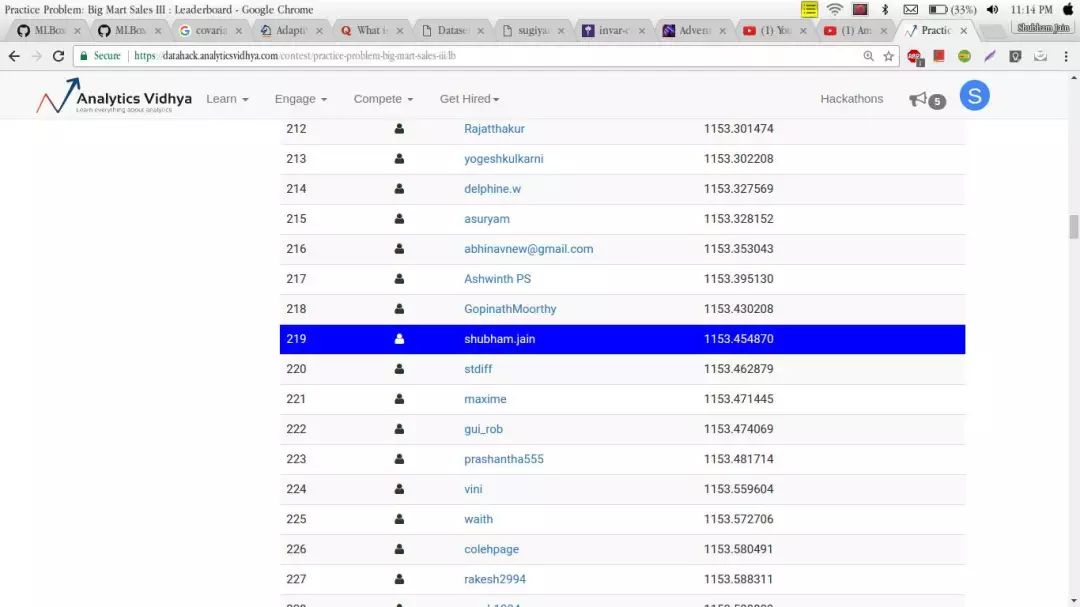
成绩还算理想,不过我仍希望进一步提升表现。为此,我着手探寻能够提升排名的改进措施。最终,我确实发现了一种有效途径,这种方法被称作遗传算法。将此方法运用到超市销售案例分析中,我的得分迅速攀升,最终在排行榜上位列顶尖位置。
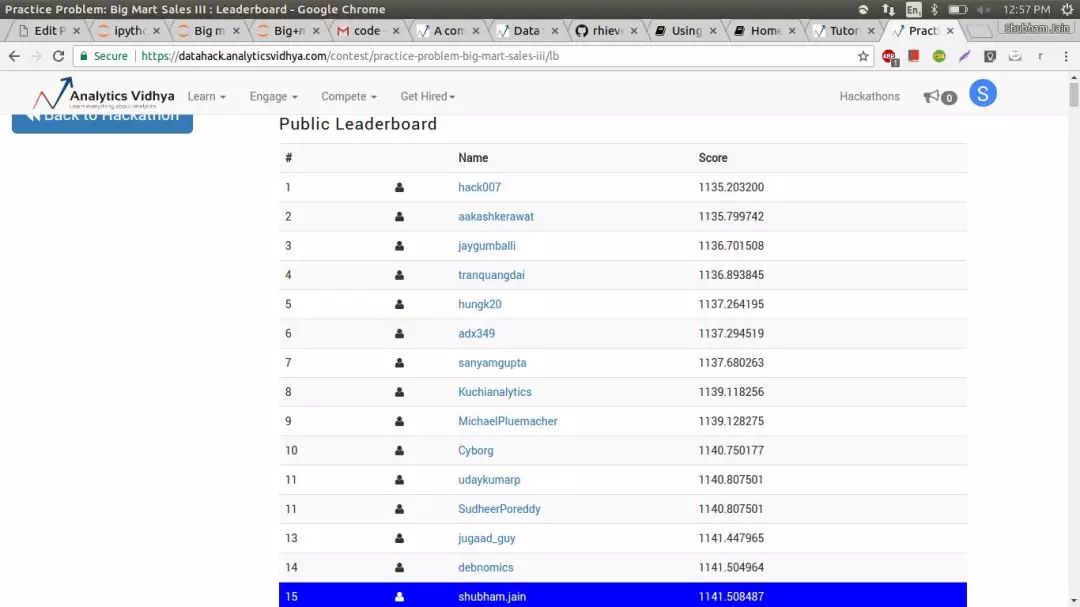
确实,我单凭遗传算法,就由最初的 219 人直接跃升至第 15 位,这难道不令人惊叹吗?只要认真阅读完这篇文章,你同样能够熟练运用遗传算法,并且当你将它运用到你正在处理的问题上时,会发现其效果会有显著改善。
目录
1、遗传算法理论的由来
2、生物学的启发
3、遗传算法定义
4、遗传算法具体步骤
5、遗传算法的应用
6、实际应用
7、结语
1、遗传算法理论的由来
我们先从查尔斯·达尔文的一句名言开始:
能够存活下来的,通常不是力量最雄厚的物种,也不是头脑最灵光的物种,而是最能融入环境的物种。
你可能在思考:这个论述与遗传算法有何关联?事实上,遗传算法的全部思想正是源于这个论断。
让我们用一个基本例子来解释 :
我们设想一个场景,此刻你是一位君主,为了让你的国度远离祸患,你推行了一系列律法,
你选出所有的好人,要求其通过生育来扩大国民数量。
这个过程持续进行了几代。
你将发现,你已经有了一整群的好人。
这个情形虽然并非现实,但我选用它旨在让你掌握要领。换言之,我们调整原始数据(诸如:人口),便能得到更理想的成果(诸如:更优越的国家)。此刻,我料想你已对核心思想略知一二,觉得遗传算法的内涵应当与生物科学关联。接下来,我们简要探讨几个关键点,以便串联起整体认知。
2、生物学的启发
你一定记得那句话:生命体都以细胞为基本单位。由此可见,任何生物的每一个细胞内部,都包含着一套完全相同的遗传物质。这种遗传物质,是由脱氧核糖核酸构成的复杂结构。
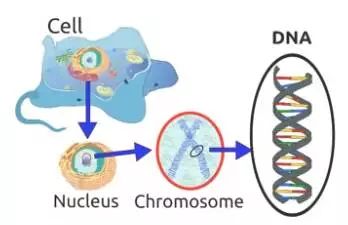
这些染色体在传统角度下,能够用包含零与一的序列来描述开元棋官方正版下载,每个字符分别对应不同的基因信息。
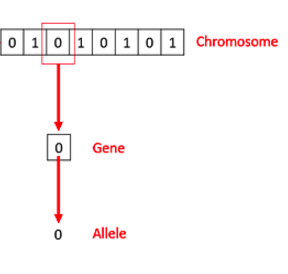
一条染色体包含基因,基因是 DNA 的基础构造,DNA 上的每个基因负责决定一个特定特征,例如头发或眼睛的色泽,请你阅读下文前,先回顾一下这些生物学知识,这部分内容到此结束,接下来,我们探讨一下遗传算法究竟是什么。
3、遗传算法定义
首先我们回到前面讨论的那个例子,并总结一下我们做过的事情。
首先,我们设定好了国民的初始人群大小。
然后,我们定义了一个函数,用它来区分好人和坏人。
再次,我们选择出好人,并让他们繁殖自己的后代。
最终,这些子孙取代了先前民众中的某些恶人,并且持续进行此类更迭。
遗传算法运作方式确实如此,它主要是在一定程度上模仿进化过程。
所以,要明确界定遗传算法,可以视其为一个改进方案,旨在探寻特定条件,依据这些条件便能获得最优结果或数值。该算法的运作原理借鉴生物学科,详细步骤参见图示。
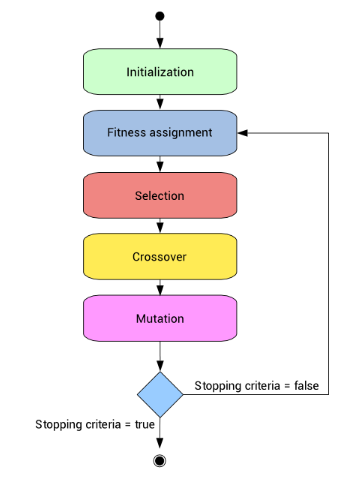
那么现在我们来逐步理解一下整个流程。
4、遗传算法具体步骤
为了让说明更加清晰,我们先来认识一下广为人知的组合优化课题「背包问题」。如果你感到困惑,这里有一个我个人的阐释方式。
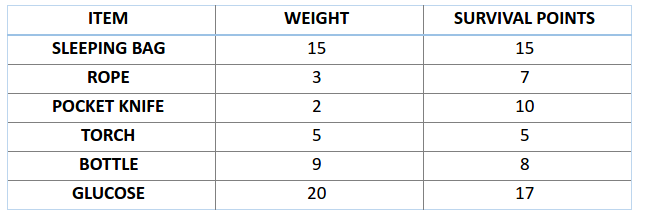
比如,你打算外出旅行一个月,然而你仅能携带一个承重为三十公斤的背包。现在你有若干必备物品,每件物品都对应着特定的「生存价值」(详细数据将在下表展示)。所以,你的任务是在背包的重量限制内,尽可能提升整体的「生存价值」。
4.1 初始化
此处我们借助遗传算法处理背包难题,首要步骤是构建整体框架,整体框架内由多个独立单元组成,每个独立单元都携带一套独特的基因序列。
我们清楚,染色体能够转化为二进制序列,其中,1 表示后续位置的基因是存在的,而0 则表明基因已经缺失。作者在此运用染色体与基因的概念来处理先前的背包难题,特定节点的基因对应背包问题表格中的物件,例如首位节点代表睡袋,那么该染色体的首个基因即体现这一物件。
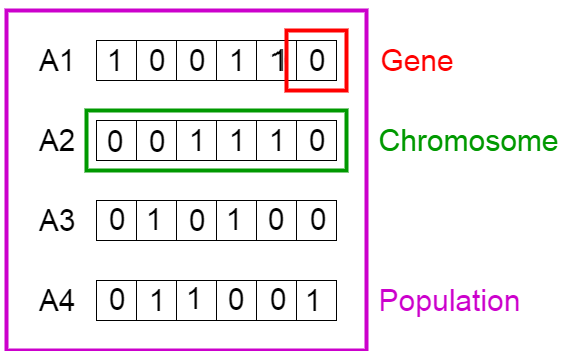
现在,我们将图中的 4 条染色体看作我们的总体初始值。
4.2 适应度函数
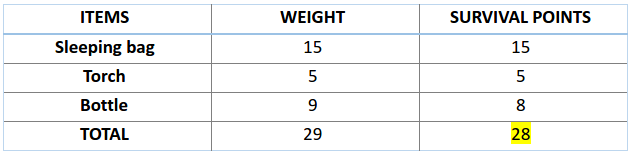
现在,我们开始评估前两个染色体的适应度值,其中涉及 A1 染色体
100110
而言,有:
类似地,对于 A2 染色体
001110
来说,有:
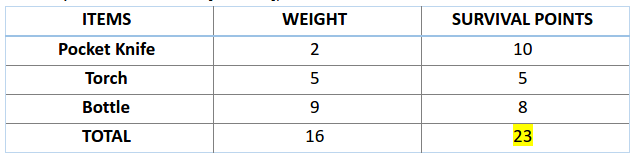
我们觉得,染色体里生存分数越高,说明它越能适应环境。
因此,由图可知,染色体 1 适应性强于染色体 2。
4.3 选择
此刻,能够从整体里挑选出合适的基因链,让它们彼此『结合』,繁衍出新的后代了。这是实施挑选过程的基本思路,不过如此一来,基因链在几代之后彼此间的相异程度会降低,丧失了丰富性。所以,我们通常采用「轮盘赌选择法」(Roulette Wheel Selection method)。

设想一个圆盘,现在将其划分成若干区段,这些区段的数量对应着全部染色体的数目。每条染色体在圆盘上占据的范围大小,会依据其适应度值进行相应比例的分配。
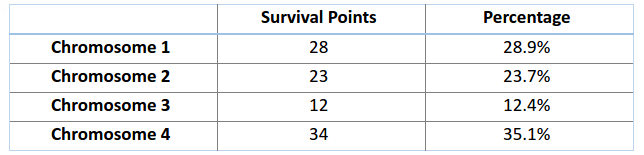
基于上图中的值,我们建立如下「轮盘」。
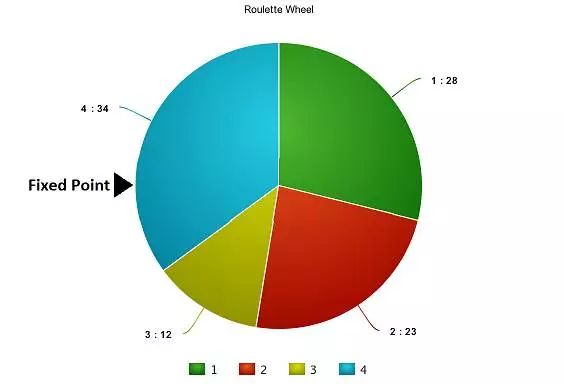
此刻,这个轮盘开始转动,我们将依据图中那个固定的指示点,选定轮盘上被它指向的部分作为首个亲本,接着,对第二个亲本也执行相同的步骤,有时我们会在过程中设定两个固定的指示点,就像图里展示的那样
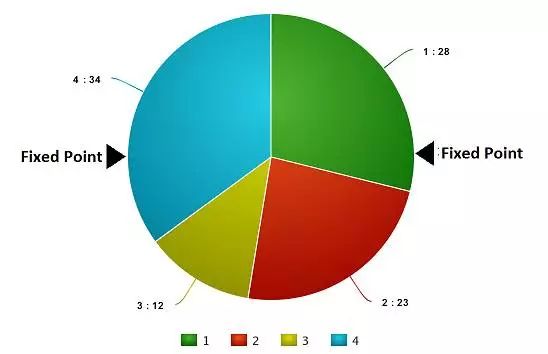
运用这种技术,我们能在单次操作里得到两个亲本个体,我们将此技术命名为「随机普遍选择法」。
4.4 交叉
先前环节已筛选出具备繁殖能力的父本基因链,所谓配子结合,在生物学上即表示繁衍过程。接下来针对第 1 条与第 4 条基因链(经由前一步骤选定),实施配子结合,具体形态如下图所示
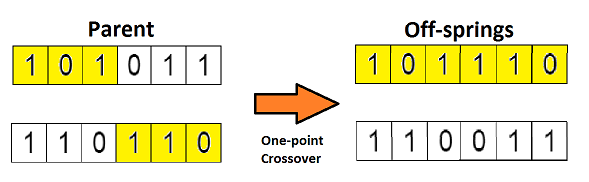
这是最基础的杂交方式,我们称之为「单点杂交」。在此过程中,我们随机确定一个杂交位点,接着,将此位点两侧的基因片段在配子之间进行互换,由此创造出新的后代个体。
设置两个交叉点,这种方法称作「多点交叉」,参见图示。
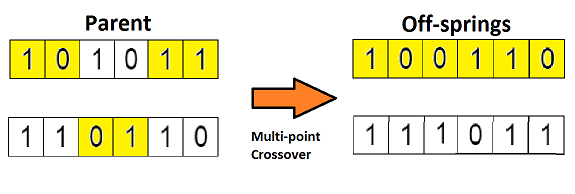
4.5 变异
从生命科学的角度审视此事,那么要知道:经由前述演变繁衍的后代,其特征是否与亲代一致呢?答案并非如此。在子代发育期间,其内部遗传物质会经历若干更迭,因而显现出与双亲相异的性状。此现象称作「变异」,它指的是染色体制造中出现的偶然性改变,正因如此,群落内才会形成丰富性。
下图为变异的一个简单示例:

基因发生改变后,我们就获得了全新生物,物种演变也就到此结束,整体流程见下图,
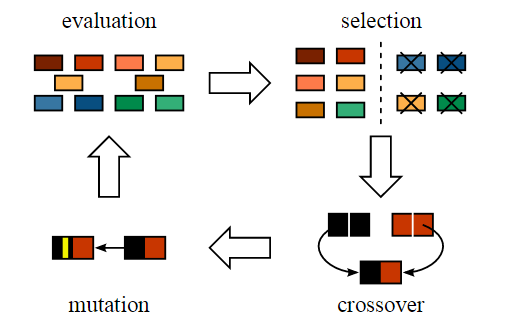
完成「遗传变异」环节后开元ky888棋牌官方版,我们借助适应度函数检测新生成的后代,当函数确认其符合标准时,就用这些个体替换掉那些表现不佳的基因型,这里面有个疑问,我们究竟该依据什么尺度来判定后代已经达到最理想的适应程度呢?
一般来说,有如下几个终止条件:
在进行 X 次迭代之后,总体没有什么太大改变。
我们事先为算法定义好了进化的次数。
当我们的适应度函数已经达到了预先定义的值。
现在,我假定你已大致掌握了遗传算法的核心思想,接下来,我们将其运用到数据科学的实际情境中去。
5、遗传算法的应用
5.1 特征选取
设想一下,在数据科学竞赛中,你如何挑选对目标变量预测有显著影响的特点呢?你通常会评估模型中各个特点的重要性,然后人为确定一个界限,选取重要性超过这个界限的特点。
目前,是否存在某种途径能够更有效地应对这一挑战?事实上,在解决特征挑选工作方面,遗传算法堪称顶尖的方法之一。
我们先前解决背包问题的思路完全适用于当前情境。首先,我们着手构建「染色体」的总体框架,这里的染色体本质上是一系列二进制数字,其中「1」代表模型采纳了某个特征,「0」则意味着模型舍弃了该特征。
然而,存在一个差异,就是我们的评估指标需要调整。这个评估指标是本次竞赛准确性的衡量标准。换言之,染色体的预测结果越精确,就能表明它的评价越好。
我现在料想你已对这方法略有所知了。接下来,我不会立刻阐释这个难题的应对步骤,而是要引导大家先运用 TPOT 库来达成这个目标。
5.2 用 TPOT 库来实现
这部分就是你最初阅读本文时心中最终期望达成的那个目的。也就是:达成。现在我们先简要了解一下 TPOT 库,它是依据 scikit-learn 库构建的。该库运用的是树形传递优化技术。下面展示的是一种基础的传递构造。
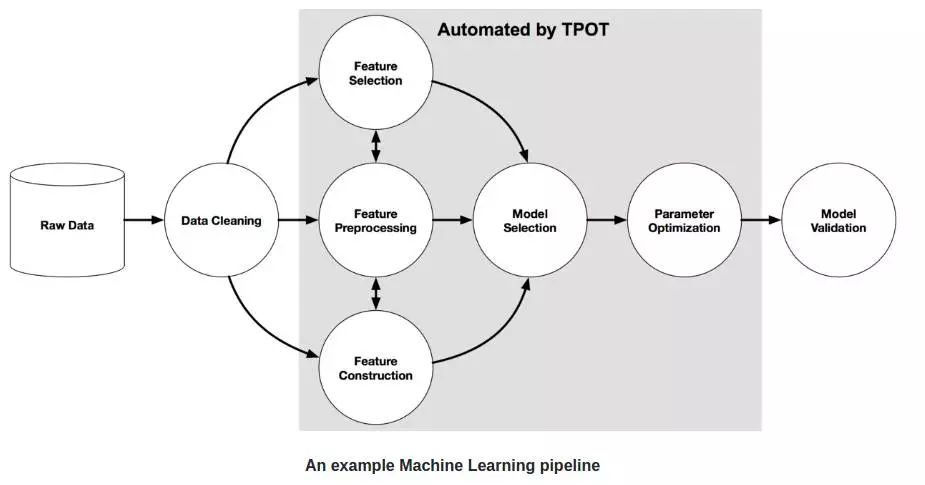
图中那个灰色的部分是借助 TPOT 库自动完成的。完成这一部分自动处理的方法是运用遗传算法。
我们不作详尽阐释,仅直接实践。要运用 TPOT 库,必须先配置 TPOT 构建所依赖的若干 python 库。接下来迅速完成这些安装工作:
安装深度进化算法工具包,升级检查模块,以及进度条库
安装deap软件包,接着更新检查工具,然后添加tqdm库
# installling TPOT
pip install tpot
这里,我选用了 Big Mart Sales(数据集地址:https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/)这个数据集,为后续工作做筹备,我们先迅速获取训练和测试数据,具体用到的 python 代码如下:
# import basic libraries
首先加载必要的库,包括numpy, pandas和matplotlib.pyplot, 并设置matplotlib inline模式以便在notebook中直接显示图形开元ky888棋牌官网版,接着从sklearn库中导入preprocessing和mean_squared_error用于数据预处理和计算均方误差,最后准备进行数据预处理步骤
### mean imputations
train
‘Item_Weight’
.fillna((train
‘Item_Weight’
.mean()), inplace= True)test
‘Item_Weight’
.fillna((test
‘Item_Weight’
.mean()), inplace= True)
脂肪含量仅分为两种类型
train
‘Item_Fat_Content’
= train
‘Item_Fat_Content’
.replace(
‘low fat’, ‘LF’
‘Low Fat’, ‘Low Fat’
) train
‘Item_Fat_Content’
= train
‘Item_Fat_Content’
.replace(
‘reg’
‘Regular’
) test
‘Item_Fat_Content’
= test
‘Item_Fat_Content’
.replace(
‘low fat’, ‘LF’
‘Low Fat’, ‘Low Fat’
) test
‘Item_Fat_Content’
= test
‘Item_Fat_Content’
.replace(
‘reg’
‘Regular’
) train
‘Outlet_Establishment_Year’
= 2013- train
‘Outlet_Establishment_Year’
test
‘Outlet_Establishment_Year’
= 2013- test
‘Outlet_Establishment_Year’
train
‘Outlet_Size’
使用空值填充为‘Small’,并且将更改应用到原数据集上
‘Outlet_Size’
用空值替换为‘Small’,并使更改生效在训练集上
‘Item_Visibility’
= np.sqrt(train
‘Item_Visibility’
)test
‘Item_Visibility’
= np.sqrt(test
‘Item_Visibility’
)col =
商品出口规模,销售网点地理位置,店铺经营类型,商品脂肪含量
test
‘Item_Outlet_Sales’
将测试集添加到训练集中,针对每一列,进行组合操作
= number.fit_transform(combi
.astype( ‘str’)) combi
= combi
转换数据类型为对象类型后的训练集等于组合数据集
:train.shape
test = combi
train.shape
test删除了名为“Item_Outlet_Sales”的列,操作影响原数据集,该列不再保留。
## removing id variables
tpot_train = train.drop(
识别出口径代号,明确物品种类,确定物品编号
轴方向为1的tpot测试集,等于测试数据集删除指定列后的结果
‘Outlet_Identifier’, ‘Item_Type’, ‘Item_Identifier’
,axis= 1)target = tpot_train
‘Item_Outlet_Sales’
tpot_train删除了名为“Item_Outlet_Sales”的列,操作是在原数据集上进行,不再保留原始数据集。
最终借助tpot库来构建模型
从tpot库中导入TPOTRegressor模块,将tpot_train和target进行训练集和测试集的划分,划分比例为75%和25%,分别赋值给X_train, X_test, y_train, y_test,使用TPOTRegressor创建一个机器学习模型,设置进化代数为5,种群大小为50,详细输出级别为2,用该模型对训练数据进行拟合,输出模型在测试数据集上的得分,将训练得到的最佳模型流程导出为tpot_boston_pipeline.py文件
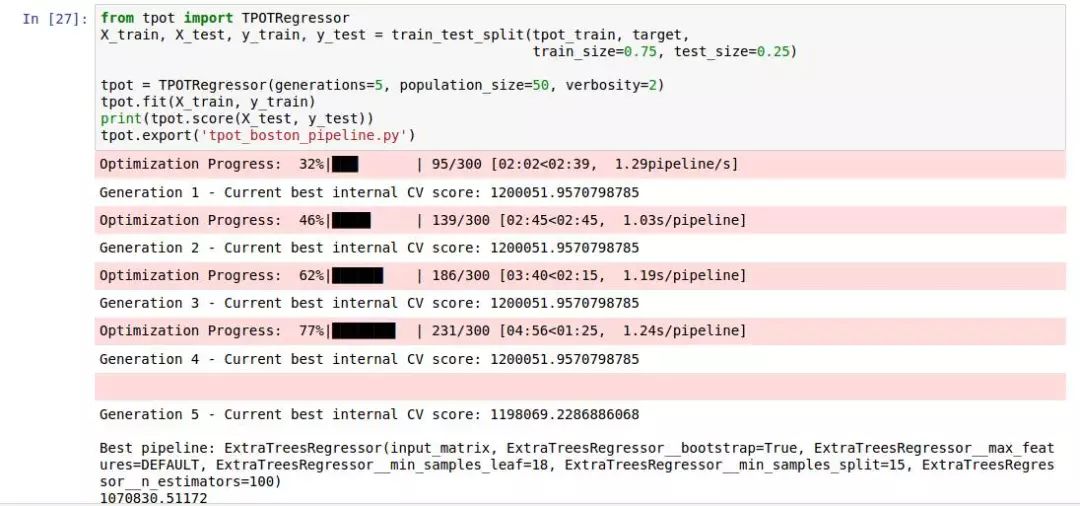
当这些代码执行完毕,tpot_exported_pipeline.py 文件中就会包含执行路径优化的 python 代码片段。经过观察,ExtraTreeRegressor 模型能够最有效地处理该问题。
进行预测,借助经过tpot优化的流程
tpot_pred由tpot对tpot_test进行预测得出,sub1是一个数据框,其数据来源于tpot_pred
将sub1的索引设置为从零到测试数据长度的整数序列,每个数值递增,并在末尾增加一个额外的数值
sub1将列名‘0’更改为‘Item_Outlet_Sales’,sub1完成这一操作
‘Item_Identifier’
= test
‘Item_Identifier’
sub1
‘Outlet_Identifier’
= test
‘Outlet_Identifier’
sub1.columns =
商品销售额,商品唯一编号,店铺唯一编号
sub1 = sub1
物品识别码,店铺识别码,商品销售额
将数据保存为名为tpot的文件,不包含行索引
若你递交了这份表格,便会察觉先前承诺的内容尚未全部兑现。这难道意味着我在欺瞒大家么?绝非如此。事实上,TPOT 工具遵循一项基本准则。倘若你未让 TPOT 长时间执行,它便无法为你所面临的情况寻得最优解决方案。
因此,需要提升算法的迭代次数,端起一杯咖啡到户外散散步,剩下的工作就让 TPOT 来完成。不仅如此,这个工具也能用于解决分类类的任务。更多细节请查阅这个网址:http://rhiever.github.io/tpot/。除了竞赛场合,日常生活中也有很多地方可以运用遗传算法。
6、 实际应用
遗传算法实际应用广泛。列举部分案例,不过受限于篇幅,无法逐项阐述。
6.1 工程设计
工程构想高度倚重数字构造与推演,如此方能令构思阶段既迅速又划算。基因法则能在此处加以改善,并产生一个极好的成效。
相关资源:


